16/09/2025 - 09:00:00 por Fabio Baccaglioni
- 4575 - 8 - En Programación
El título ya es complicado, pero les juro que lo que sigue... bueno, es también complicado 😁
Nah, vamos a tratar de explicarlo. N8N es un software que te permite crear "Agentes de AI" en tu propio entorno. Si bien nadie define bien qué es un agente está muy bueno para experimentar con workflows que combinen herramientas que tenemos. Lo bueno es que es conectar cajitas con cajitas, bien visual, sin necesidad de código fuente. Eso lo hace muy "APB" al mismo tiempo que tiene sus obvias contras.
Aclaro: N8N es propietario, así que para uso profesional mejor apuntar a la versión paga, pero para aprender es ideal instalarlo en local. ¿Pagaría por esto? Pues no, pero ya me han consultado por este soft y quería verlo más de cerca, especialmente la versión "community" cuasi-gratis.
Ejemplo de qué hace: lee del RSS del blog donde publiqué una nota, la toma del browser, se la pasa a ChatGPT para que haga un resumen, la postea en Facebook y te envía un email para avisarte. Todo eso en un simple click o automatizado. ¿Suena imposible? No, es exactamente para lo que se inventó.
Ahora bien ¿Y si queremos tener todo local? Por eso entra la parte de Ollama, les sigo explicando...
Ollama es un motor para tener tus propios modelos de AI corriendo localmente, así como LM Studio sirve para chatearle directamente, ollama hace lo mismo pero con un programa más pequeño que automáticamnete abre un servicio para que cualquier otro programa lo llame.
Esto es muy interesante para desarrollar nuestras propias ideas locas que usen un LLM, ya sea un juego o un programa, o, como en este caso, un agente.
¿Por qué meter todo en Docker? Pues porque n8n es un martirio de instalar fuera de Docker, y Ollama también es conveniente, todo compartimentado, todo borrable fácilmente.
Docker no sólo crea espacios bastante seguros, también usa los recursos del hardware de forma directa, no es virtualización del todo, un poco sí porque en Windows está usando WSL, que es Linux en Windows, pero no voy a entrar en detalles, lo cierto es que... no podría usar n8n y hacerlo funcionar correctamente 😁 y no tengo ni las ganas ni el tiempo de hacerlo.
Docker no es lo mío, pero ponerme a leer millones de foros tampoco, así que vamos a lo nuestro.
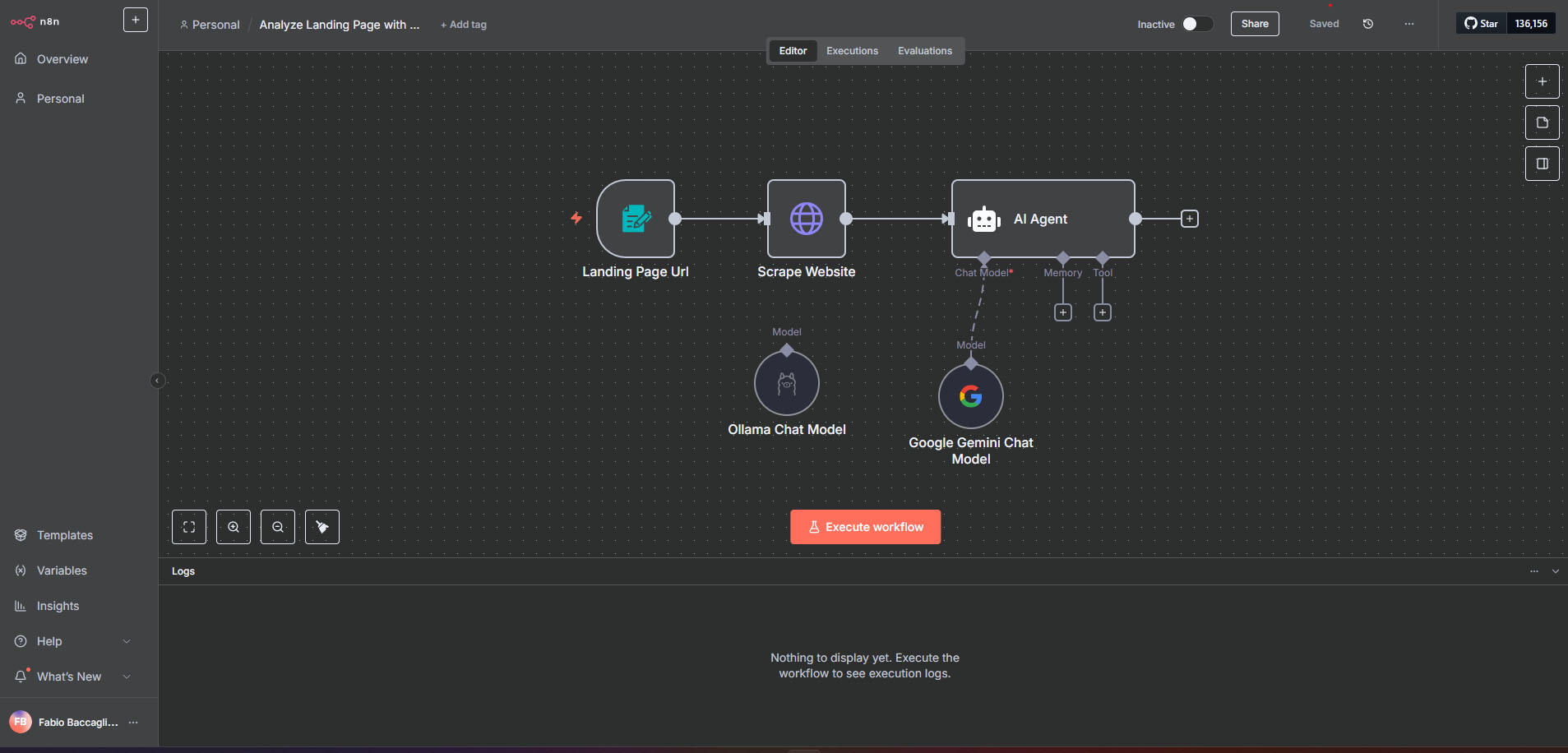
El orden de los factores
Ningún tutorial te explica correctamente cómo hacer esto y esto tampoco es un tutorial: es como yo logré hacerlo funcionar, así que se aceptan sugerencias en los comentarios porque estoy seguro que más de uno de ustedes lo hace mejor que yo.
El problema que me encontré con N8N es que vive en su propia burbuja y nadie te dice eso, aprendí a las patadas que uno puede crear "redes" dentro de Docker. Así es, como una LAN interna que conecta containers entre sí, algo bastante conveniente si justo queremos hacer funcionar dos y que se vean mutuamente.
Así que lo primero que hice fue crear una:
docker network create redinterna
Me jugué con el nombre, pero es importante recordarlo 😋 porque todo lo que generamos lo vamos a tener que meter adentro de esta network.
El segundo problema con que me encontré es que ollama ejecutaba todo en CPU. Imagínense meter todo un modelo de AI en CPU cuando tenés una linda RTX 3060 al pedo haciendo nada.
Resulta que Docker puede tranquilamente usar tu GPU, el tema es que le tenés que avisar porque parece que es medio bobo todo, así que:
docker run -d -v ollama:/root/.ollama --name ollama --network redinterna -p 11434:11434 --gpus=all ollama/ollama:latest
Aquí estoy ejecutando ollama, en la red "redinterna" en el puerto 11434 (el default) y, lo más importante "--gpus=all", esto cambió todo, obviamente tengan los drivers de NVidia actualizados o no va a funcionar nada.
En esa red interna se verá como:
http://redinterna:11434
y esto les mostrará la página default de ollama, si aparece algo, es que van por buen camino.
De entrada Ollama no tiene ningún modelo, recomiendo que entren a la terminal de ollama y carguen alguna
docker exec -it ollama ollama run llama2
Yo suelo usar gemma3:1b que es ÍNFIMO y me permite con un mínimo uso de recursos tener un LLM usable. Es un modelo de Google libre de apenas 800Mb con 1B de parámetros.
Ahora hay que meterle pilas a N8N:
docker run -d -v n8n_data:/home/node/.n8n --name n8n --network redinterna -p 5678:5678 n8nio/n8n
Aquí lo importante es también avisarle que va a estar en la network "redinterna", me volvía loco tratando de conectar ollama con n8n y no entendía qué me faltaba, esto no te lo explica nadie tampoco.
http://localhost:5678/
Ahora podemos pasar a seguir los pasos de la instalación de n8n, no es gran cosa, sí te va a pedir una licencia. Tengan en cuenta que no es del todo libre, es open source, pero la empresa que lo desarrolla usa una de esas licencias que obviamente derivan en que en unos años cierran todo. Pero está bueno para aprender y experimentar.
Aquí la prueba de un workflow simple para testear que ollama y n8n se hablan:
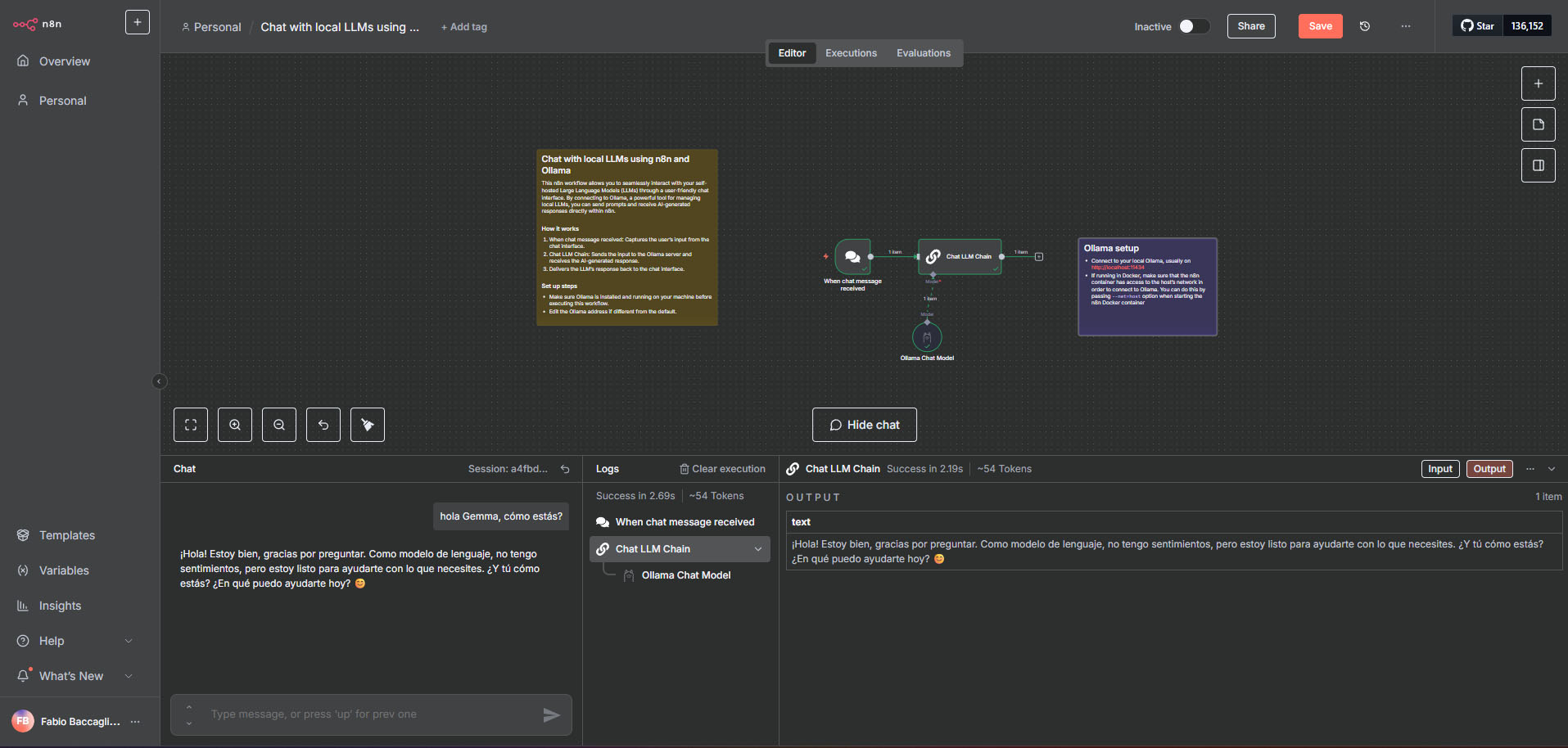
Alternativas realmente libres
Ollama es libre, pero n8n tiene su propia licencia que de un día para el otro puede cambiar, quiero una opción GPL, pero bien hecha también.
¿Alguno conoce alguna alternativa?
Por lo pronto seguiré experimentando probando las siguientes: Node-RED (lo instalé, no entendí nada, demasiado estilo "open source" del viejo en la documentación, cero capturas de pantalla 😅) y Huginn que al parecer son las que van en este momento sin tener que pasar por alguna licencia restrictiva o "curiosa" que el día de mañana pueda cerrar el desarrollo. También probé un poco Kestra, más parecido a n8n, incomprensible a primera vista 😁, pero parece mucho más potente.
Lo que tiene n8n es que está visualmente diseñada para agradar y ser entendible, en su rango están Windmill y Activepieces, todas igual, te abren el código pero no sé si son realmente libres, algunas como Activepieces seguro que no. Igualmente probaré todas las herrmientas para ver cual es mejor para cada uso que necesite.
Como alternativa a Ollama está LocalAI, ambos proyectos utilizan la licencia MIT.
¿Conocen un buen reemplazo de N8N? los leo.
Si te gustó esta nota podés...







 16/09/2025 - 09:21:38
16/09/2025 - 09:21:38
