






uffff... me paro y aplaudo el laburo.
Quien sabe como habrían sido los resultados de las elecciones sin estos tipos de ´intervenciones´ en las redes.
Hace un tiempo leí un post que decía que Trump había usado BigData para su campaña, analizaban unos pocos posts de los usuarios de fb y ya sabían clasificar los intereses de cada uno, juntaron como 250 millones de perfiles. Luego habían creado algunos perfiles en fb donde operaban a la masa votante, promocionaban posts y anuncios muy muy segmentados, a los q estaban a favor del aborto les decía algo de eso, tal vez la mitad de estos usuarios estaban en contra de acciones militares en el mundo y entonces a esos no les mostraba algo relacionado con la milicia, pero a otro tanto que estaba interesado si le mostraba. Fueron sembrando una ´idea´ de político que se interesa por tu interes y que te escucha. Esto se está yendo de las manos ![]()
Cazador de Bots: fakes y campañas en Twitter

Desde hace unos meses, en mis tiempos libres, me puse a trabajar en una aplicación renovada para analizar tanto el accionar de bots, cuentas falsas, cuentas políticas y todo el submundo de rivalidades en Twitter que se manifiesta mucho más fuerte en época de elecciones.
Era una excelente oportunidad de obtener una buena muestra de datos reales, el conflicto te brinda mucha información y hay que poder clasificarla para hacer análisis y, de paso, quería crear una herramienta que me pudiese dar información temprana, de primera mano, que pudiese capturar con muy poco tiempo de margen lo que sucedía y qué se hablaba.
Decidí centrarme en las elecciones así que mi tarea inicial era capturar una muestra de datos, catalogarlo y a partir de ahí automatizar y ésto es lo que hice y los resultados que arrojó y que sigue dando porque mi aplicación funciona todos los días sin detenerse!
Primero que nada vale aclarar que no tengo financiación de nadie para hacer esto (una lástima, es re vendible, pero las cosas a mitad de camino no deberían comercializarse ![]() ) y no hay una postura política. Son datos, y si bien aplico mi criterio personal para curar y catalogar lo que veo, es fácil de ir mejorando y purificando los datos.
) y no hay una postura política. Son datos, y si bien aplico mi criterio personal para curar y catalogar lo que veo, es fácil de ir mejorando y purificando los datos.
Para hacer todo esto tan sólo utilizo la API de Twitter para desarrolladores sin ningún aditivo, sólo con los límites que aplica Twitter a cualquier usuario menor, pero aquí hay una interesante salvedad: no hace falta más.
Rápidamente descubrí que no era necesario un volúmen bestial de datos, hacía falta encontrar el hilo que desarmaba la madeja, una cierta cantidad de usuarios clave y uno ya tiene la muestra representativa, de ahí en más pude desenroscar la red que los conecta y más allá de lo que muchos piensan no es que esté lleno de bots, está más bien lleno de cuentas falsas para simular participación y todo ocurre en un ecosistema demasiado pequeño como para mover tanto los hilos.
click para ampliar
Motivación
Me motiva a crear esto no sólo la posibilidad de desarrollar una aplicación de alerta temprana para aquellos temas que van a dar que hablar, sino para identificar algo que yo venía diciendo hace mucho pero que requería algún grado de evidencia para sustentar: La mayoría de los temas que supuestamente toca el público en las redes sociales son falsos, impuestos por militantes y operadores políticos y levantados por los periodistas con pocas luces que necesitan llenar de contenido sus medios.
Así pues lo que resaltó de dos meses de investigación fue sencillamente lo que sospechaba, la gran mayoría de los temas tratados en esta red en particular (y Facebook también pero no entra en este análisis) son impuestos, falsificados, inflados y testeados día a día hasta que uno logra la atención de algún medio o persona relevante. Luego de eso se difunden como un buen viral, desparramándose como una media verdad, media mentira, pero sembrando el tema que se deseaba insertar.
El éxito de una campaña de este tipo es que en los diarios de mañana se hable de la idea que se intentó incorporar hoy, el medio es económico, demasiado, y hasta un partido venido a menos pero con suficiente masa crítica de militantes puede hacerlo.
Desenmascarar esto es muy divertido, además desarrollar una aplicación que funcione y tenga un fin específico.
click para ampliar
Tecnología y números
Todo está montado en un sencillo servidor Linux con Nginx, Apache, PHP y MySQL, un VPS económico pero con suficiente memoria y procesador como para poder hacer querys complejos en la base de datos para estos informes.
Utilizo tan sólo una API key, el sistema fácilmente se podría extender para utilizar varias si quisiera más volúmen de datos pero con esto fue suficiente para las elecciones PASO.
Al momento de escribir este artículo cuento con 1.3 millones de tuits en la base de datos, 193k usuarios, 19k hashtags. Como verán no es tan grande, es manejable y he decidido ir borrando tuits viejos más que nada de usuarios sin catalogar.
Por cada usuario decidí analizar lo siguiente, si es Pro, si es K, si es Massa, o si es de otro partido (desde los de izquierda a Losteau me dan igual por el poco volúmen que tienen), además si es un Bot, si es Fake, si es un Troll, si es un medio, si es un operador político, si es famoso, si es un usuario relativamente normal, etc. Es caprichoso y restringe la muestra, pero es justamente lo que necesitaba hacer, acotar en base a mis posibilidades (que esto no me da dinero, che!).
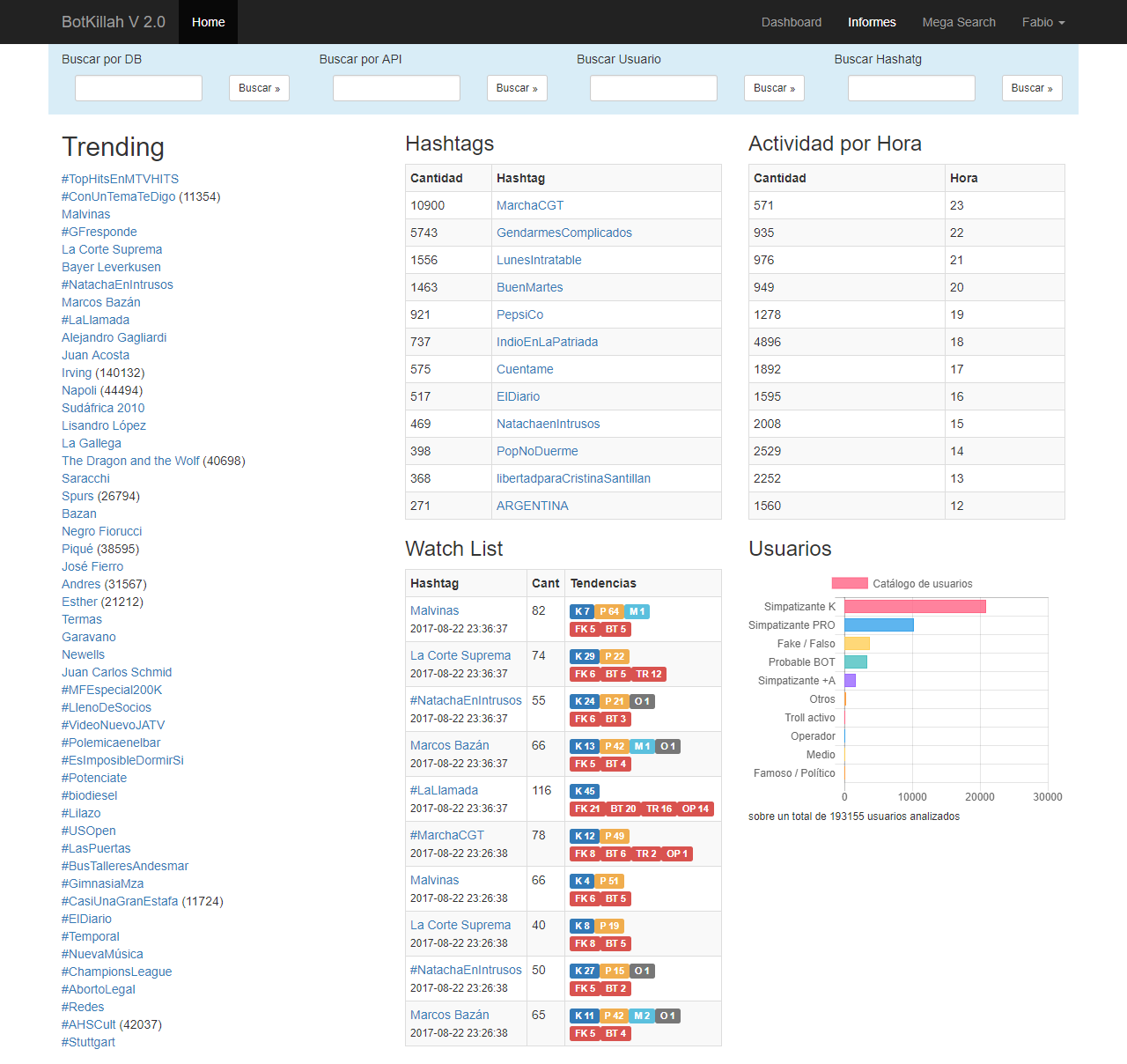
Por otra parte la aplicación tiene un servicio en cron que levanta datos permanentemente aprovechando los usuarios que ya tiene catalogados para darse cuenta qué hashtags son relevantes para inspeccionar y así alertar al usuario de prestarle atención.
click para ampliar
La aplicación
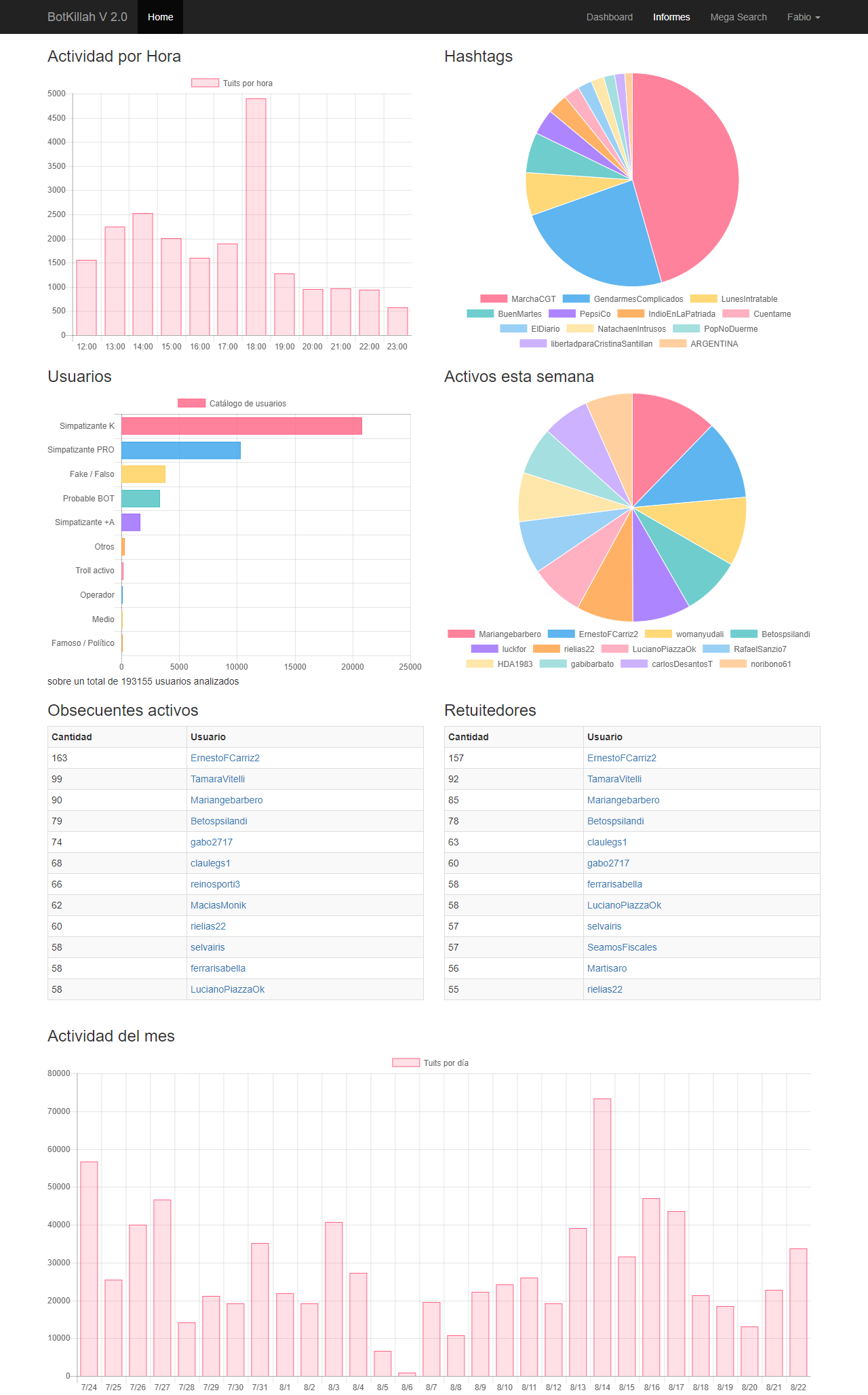
Con el nombre heredado de Botkillah 2.0 (algún día le pondré el nombre final, tomemos esto como el nombre clave del proyecto) la Aplicación tiene un index bastante sencillo pero directo, desde las 50 tendencias del día, los hashtags que más menciones tuvieron, las alertas de dónde está la masa de usuarios interesantes y la actividad hora a hora.
El sistema automáticamente toma entre 300 y 1000 tuits por hora para analizar dependiendo la actividad y sólo se queda con aquellos con usuarios ya catalogados en cantidad. De los 190k usuarios que capturé tengo analizados unos 40k, suficiente muestra de militancia
click para ampliar
Uno puede capturar más info buscando directo por la API o haciendo un "mega search" que es bastante más violento con la API y come recursos a lo loco pero me permite caputrar de a varios miles por acción.
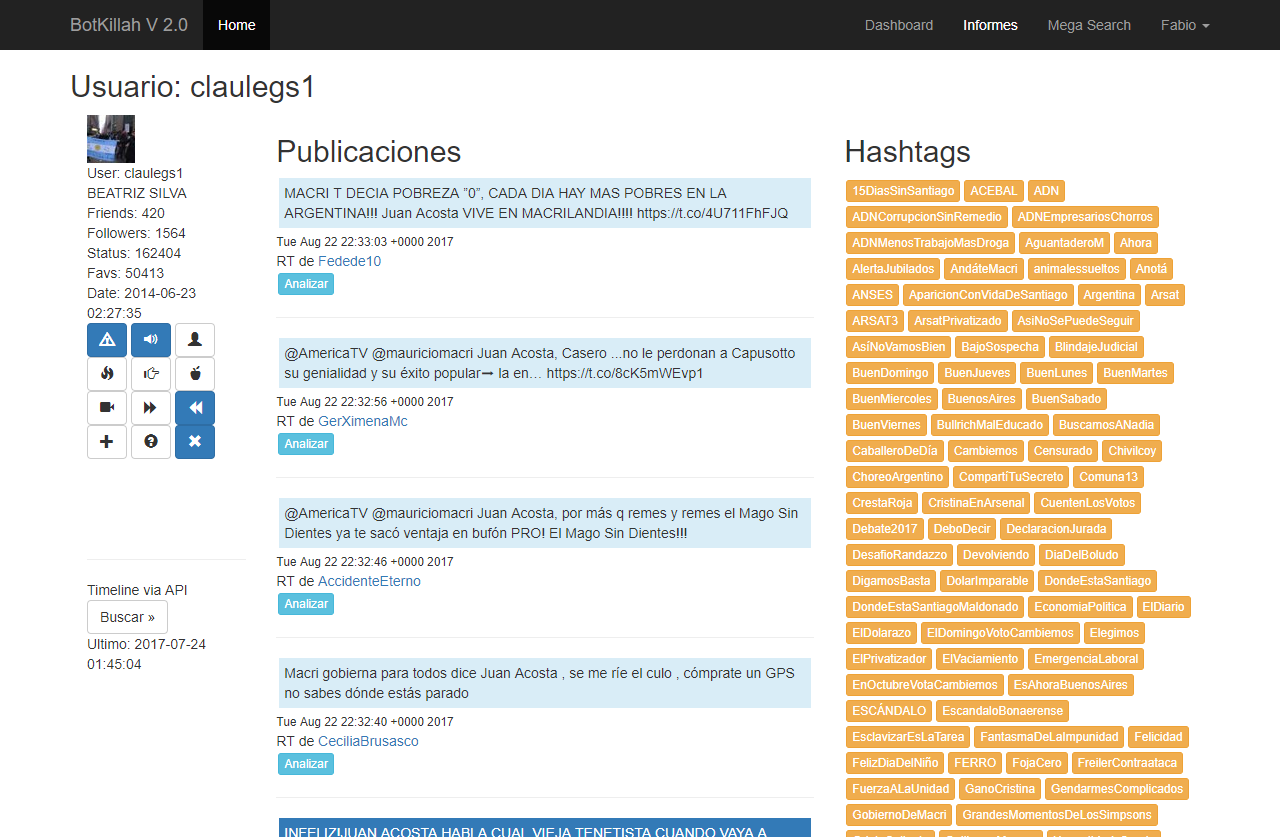
Además por cada tuit se lo puede analizar, verificar qué usuarios le dieron RT, traer todo el timeline de un usuario (ideal para confirmar su tendencia política o si es un bot retuiteador) y por cada usuario catalogarlo en cualquier momento y lugar por parte del operador.
Los resultados
Ahora les voy a contar un poco lo que estuve viendo, obviamente no soy experto en estadística ni análisis político, pero los números son lo suficientemente claros como para ver cómo se maneja el ambiente político argentino y evitar hablar sin fundamento.
El informe es sencillo y captura los datos desde el 20 de Julio de 2017 al 20 de Agosto de 2017 (hay más pero tengan piedad de mi servidor
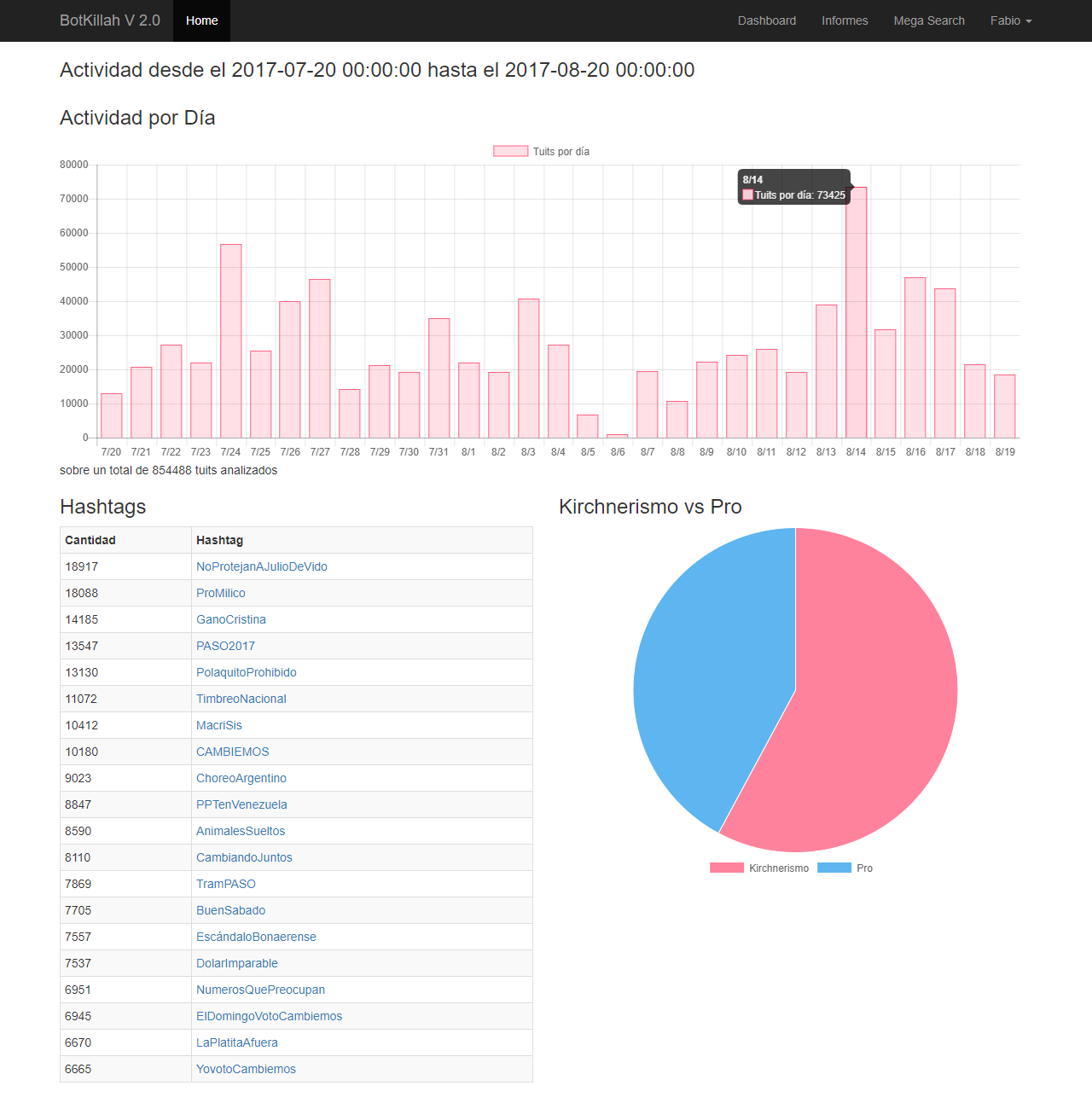
click para ampliar
Lo que es notable es que la militancia es más de utilizar los hashtags que la gente "real". Con real no quiero confundir, podría decir "el pueblo" pero Twitter no es representativo de la sociedad. Lo cierto es que aquellos que no estan muy metidos en un partido político no usan hashtags, los militantes sí.
Todos los HT que pueden ver son de índole política, no hay nada de programas de televisión o concursos ni bandas de rock o famosos, así que limpia la base de esos ruidos es obvio que hubo una constante guerra por ver quién se quedaba con la "plaza digtal".
Proporcionalmente, en cantidad de tuits, el kirchnerismo es mayoría, tienen una base de usuarios (entre falsos y verdaderos) de más del doble que el Pro y en el ruido mediático se nota. Pero por otra parte Cambiemos tiene una masa suficiente de apartidarios pero que se sumaron a varias acciones previo al comicio y se notó fuerte.
Hice cinco consultas predefinidas, Macri, Kirchner, Cambiemos, Cristina y Vidal, es muy interesante ver estos gráficos día a día y cómo progresaron, si alguien tiene ganas puede contrastarlo con las noticias del día y notará por qué fueron tan mencionados.
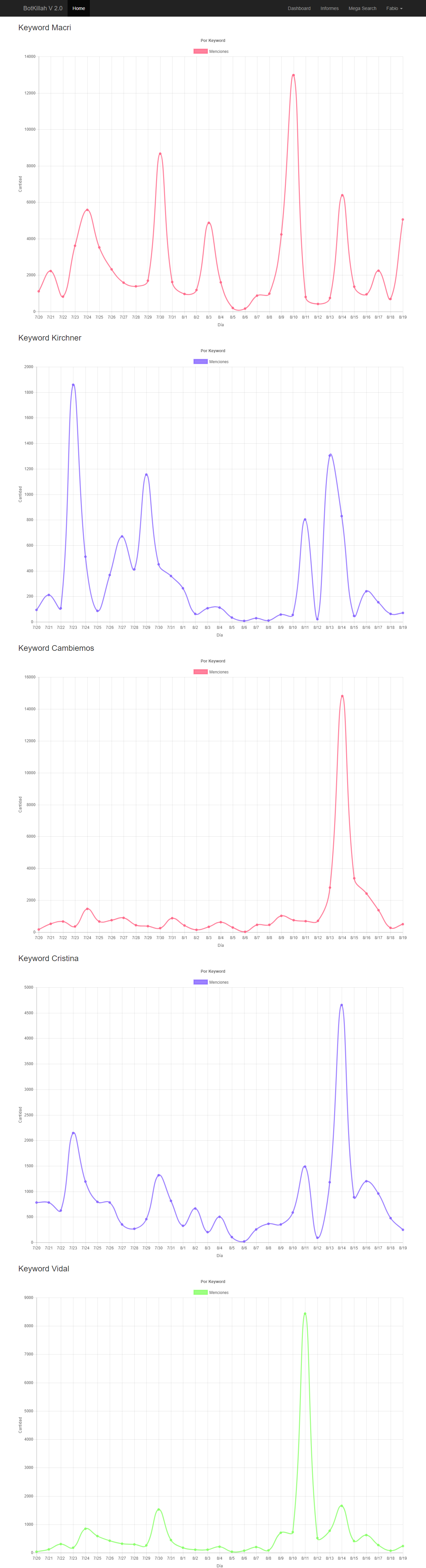
click para ampliar y ver más consultas
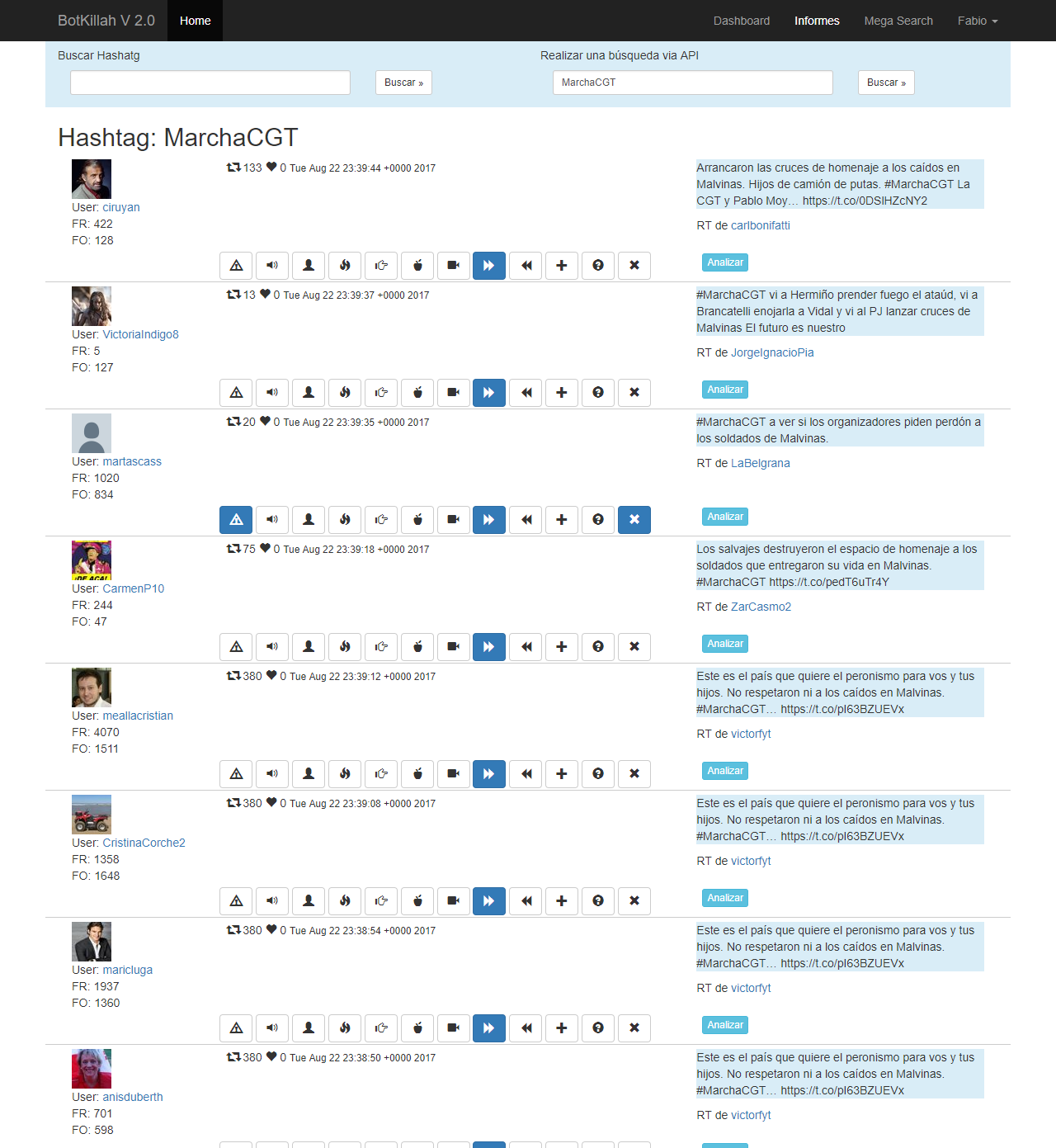
Por otra parte tomé varios de esos hashtags y entré uno por uno para ver cómo fue la acción, son muy interesantes:
#GanoCristina
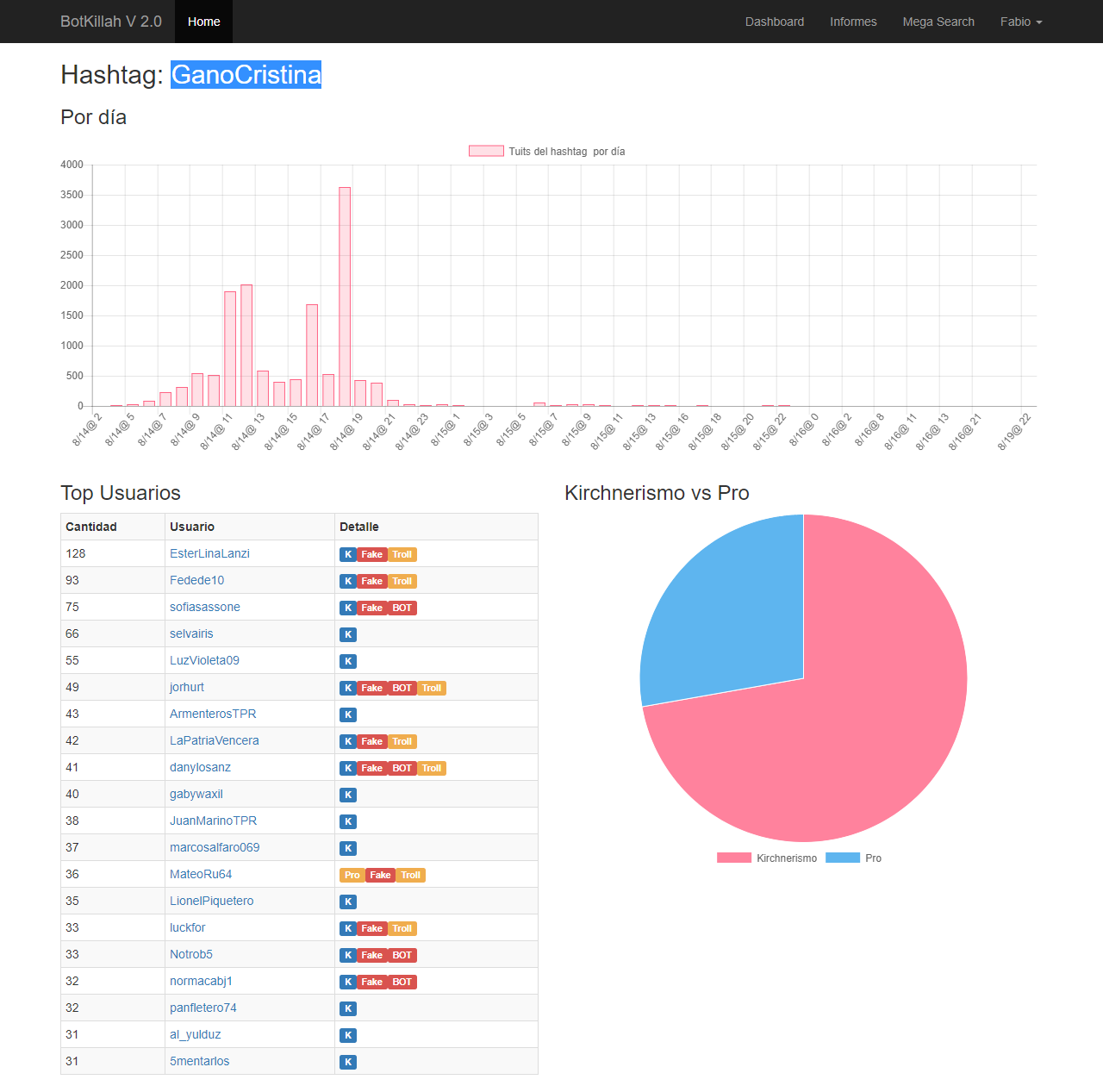
click para ampliar
#MacriSis
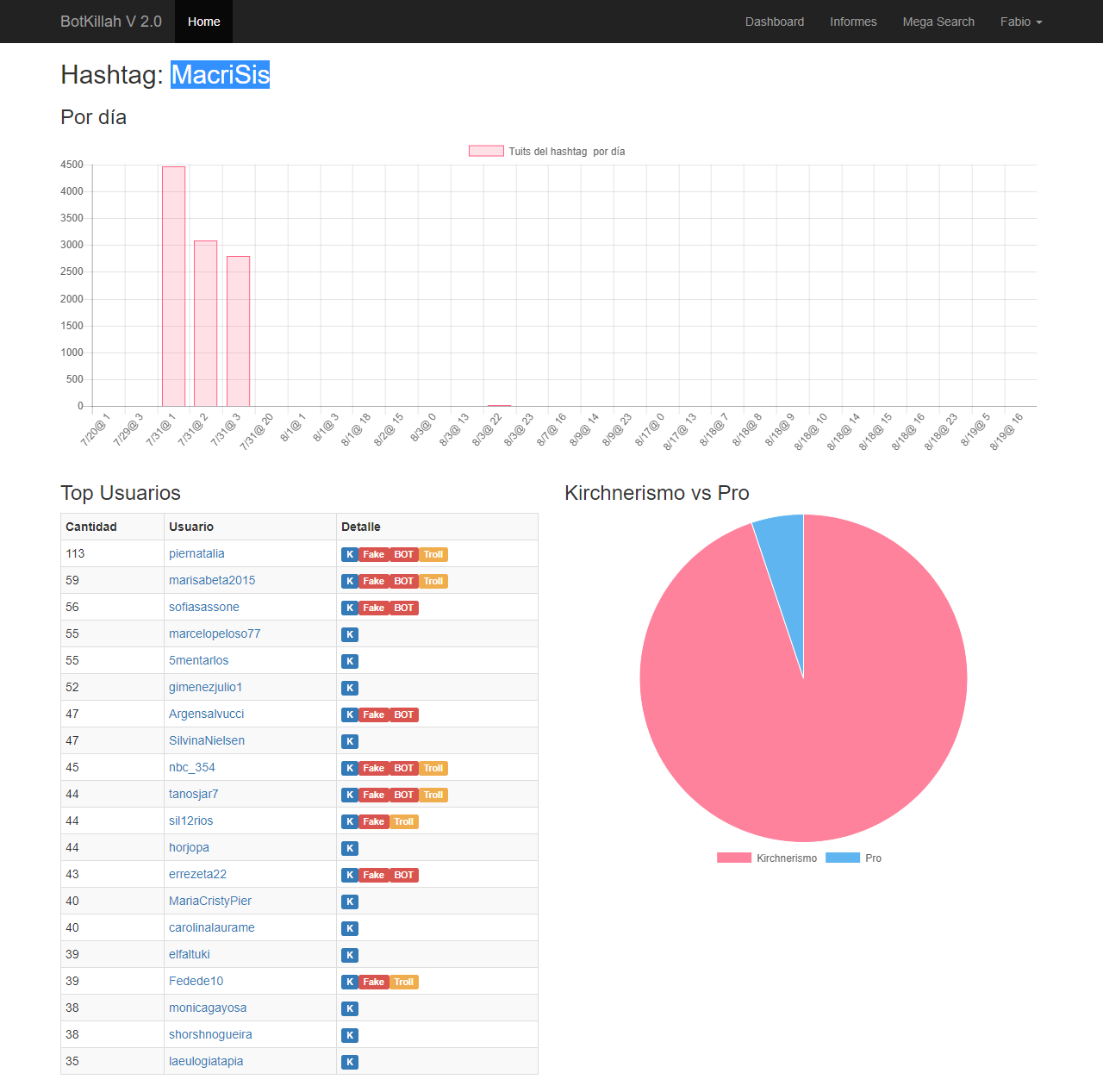
click para ampliar
#NoProtejanAJulioDeVido
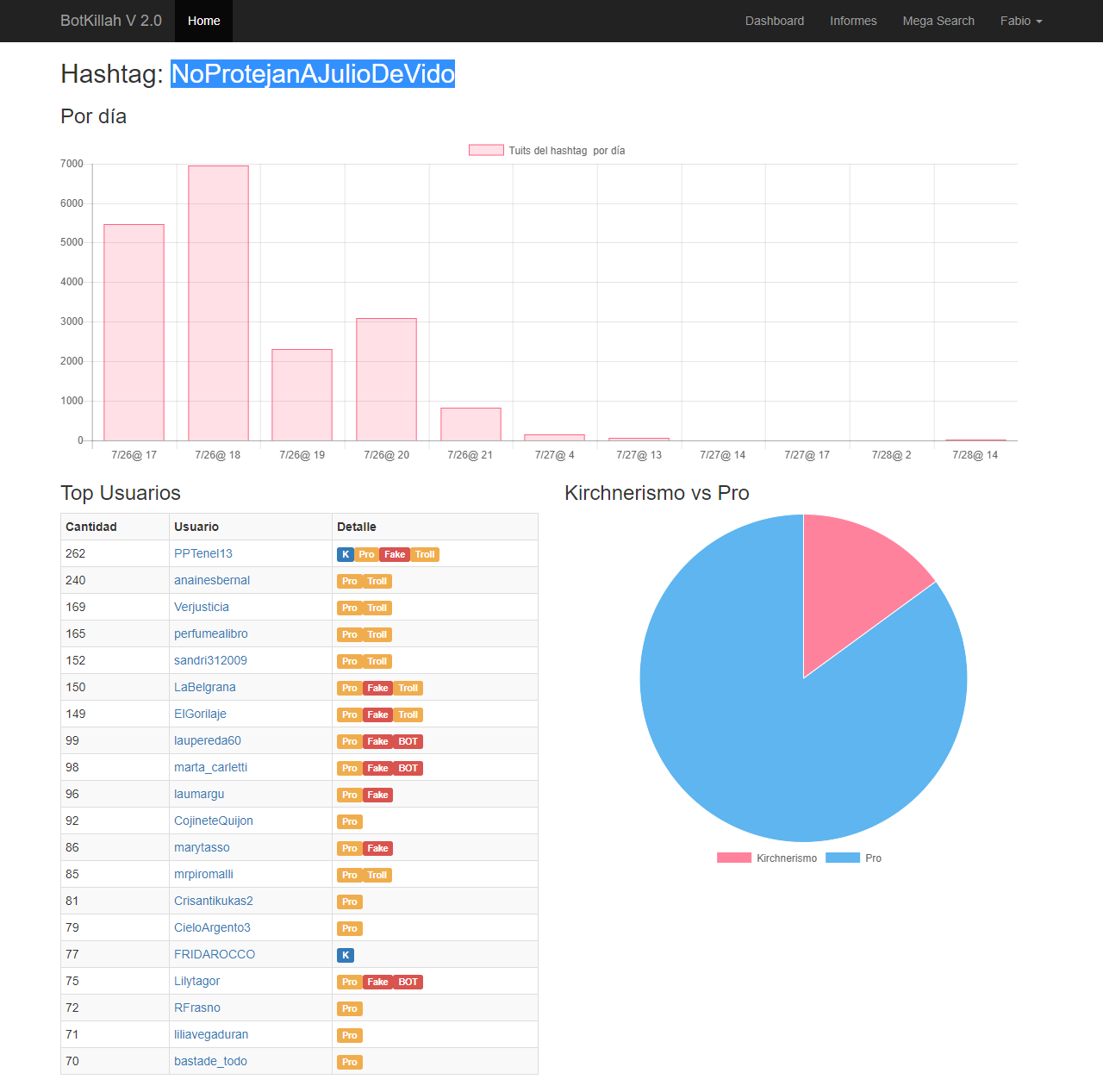
click para ampliar
#PASO2017
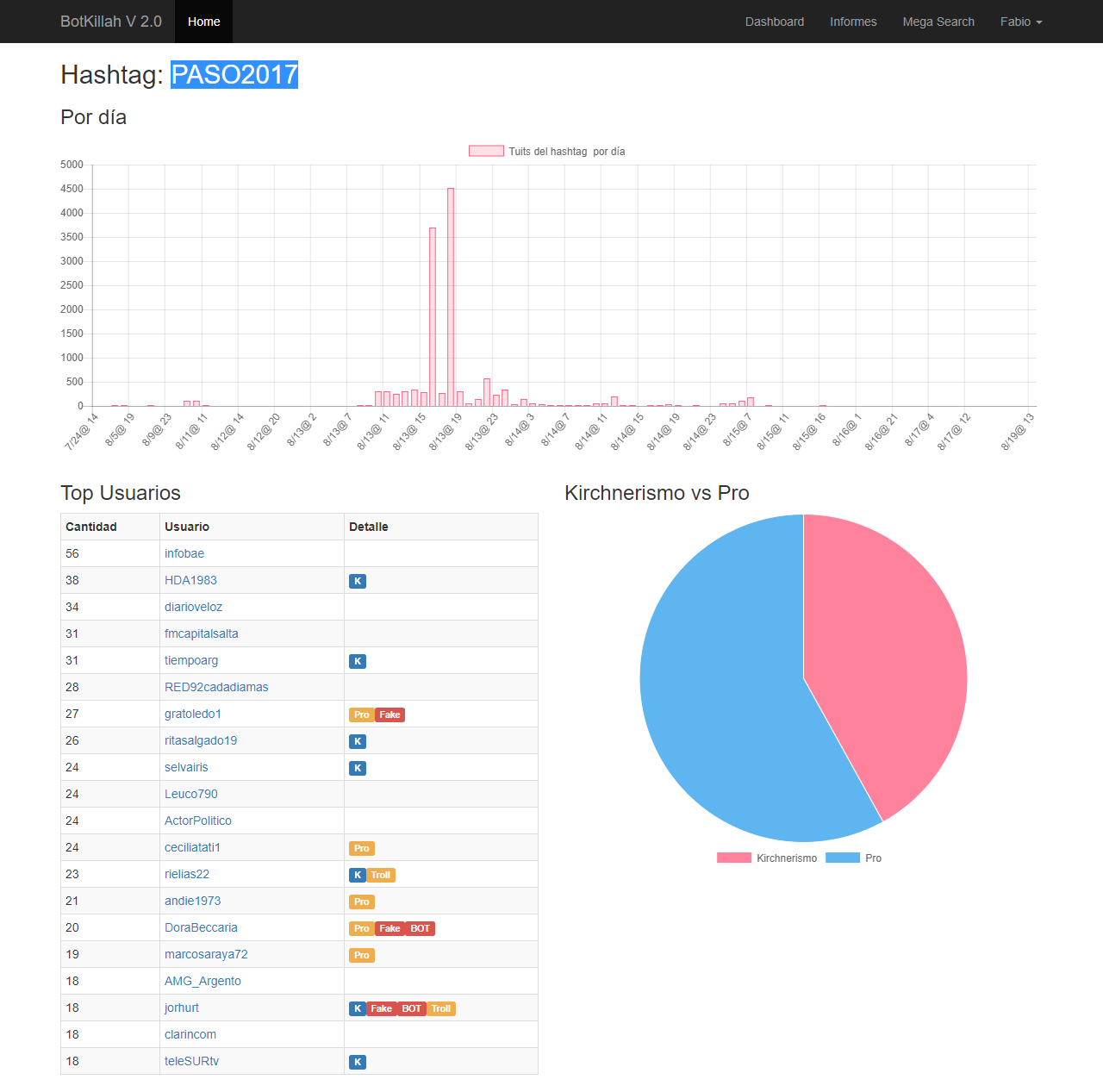
click para ampliar
#ProMilico
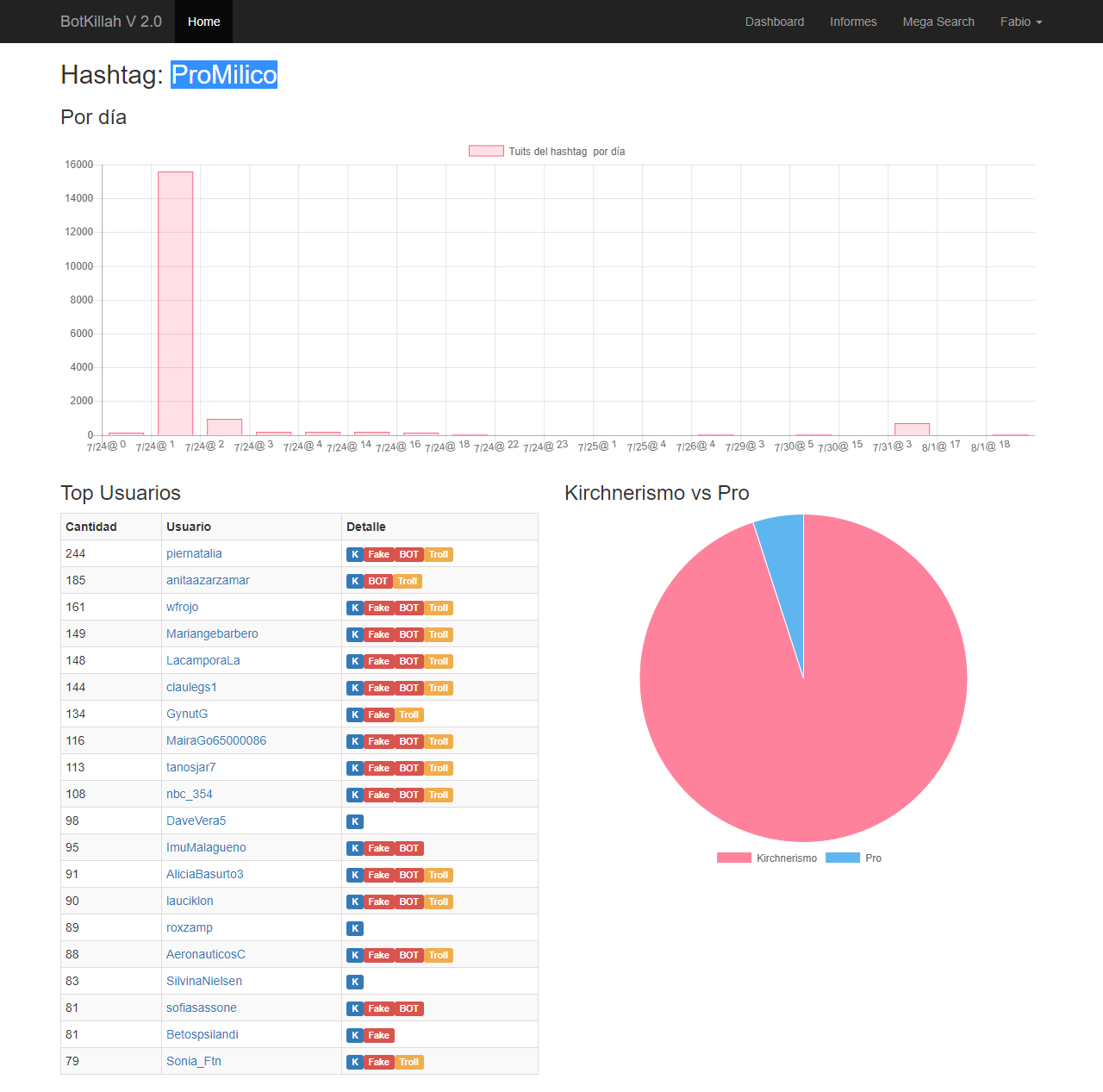
click para ampliar
#TimbreoNacional
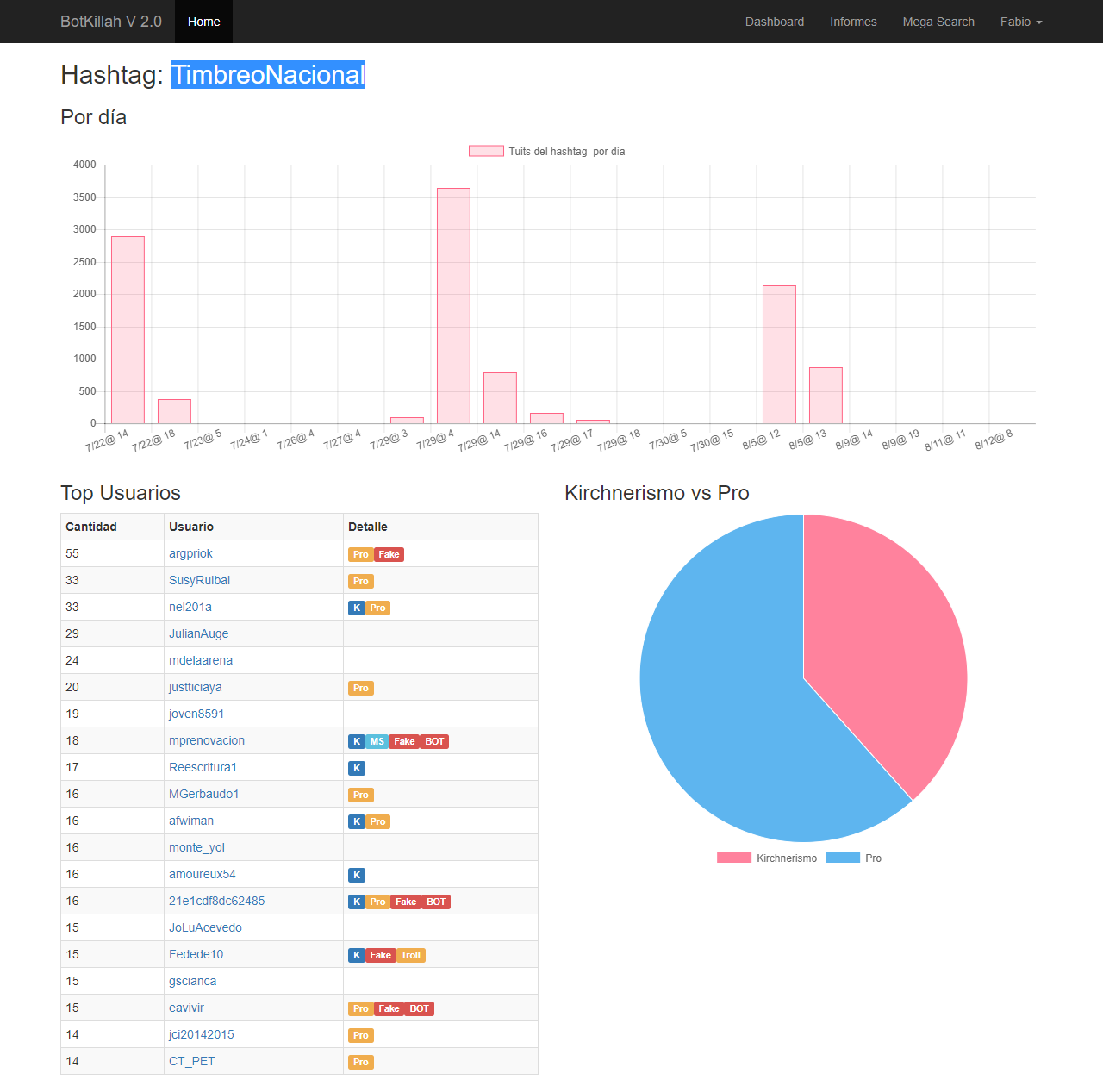
click para ampliar
#CAMBIEMOS
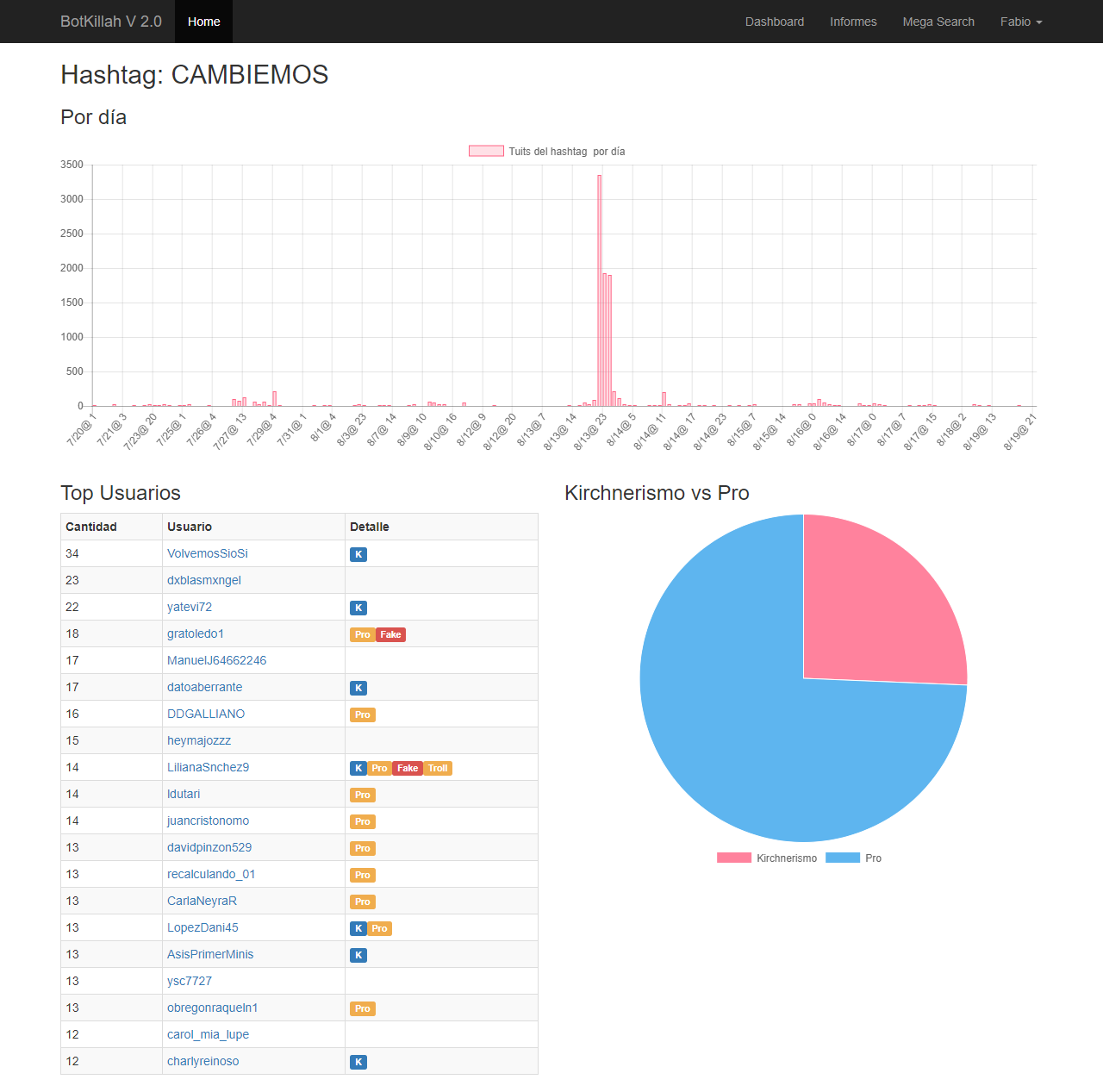
click para ampliar
Conclusión
Como notarán hay mucho para sacar de todo esto, todavía me falta terminarle algunas partes más que nada en la generación de informes, lo bueno es que pude probar que funciona, tanto la captura en tiempo real como la programada y la voluntaria, se puede juntar mucha información y estoy seguro que para las elecciones de Octubre va a ser mucho más interesante y jugoso todavía.
Desde ya que el código de esto no es tá liberado, primero que nada porque no es un código muy prolijo (lo siento, los que programamos a veces somos vanidosos), segundo porque sería ideal comercializarlo (es aplicable a cualquier tipo de acción comercial) y es mi idea poder hacerlo (sponsors bienvenidos).
Tampoco es que inventé la rueda, existen infinidad de desarrollos enlatados que hacen algo parecido, pero no vi ninguno (todavía) que se dedique a esta parte del análisis.
Para futuro quiero terminar de aprender algo como para implementar Machine Learning en dos áreas. Una en la de análisis de sentimiento, estuve probando la API de Google pero los ejemplos que brinda estan tan mal programados que nunca funcionan, imposible hacerlo bien (Odio a Google cuando no le da importancia ni a su propio negocio!).
Pero también quiero aplicar ML para identificar la tendencia política y si el usuario es real o ficticio. La base de aprendizaje ya está (40k catalogados más o menos, no digo que bien, lo hice yo sólo) y con eso se podría generar un buen modelo e ir taggeando al resto de usuarios que todavía me queda por catalogar y los que vengan a futuro.
Hay infinidad de usuarios apócrifos, cuentas creadas ad-hoc para la campaña que no tienen más que un tuit real de actividad y el resto son retuits, como una gran caja de resonancia dentro de la propia burbuja de cualquier político.
Si la masa del pueblo se diera cuenta de esto dejaría de votarlos, pero claro, la apariencia es clave en la política y la misma masa aplaude a aquél que aparenta tener un gran séquito de obsecuentes. Nadie quiere votar al perdedor! (salvo la izquierda, claro
Queda mucho por hacerle y se aceptan sugerencias, si alguno tiene un interés real también puedo darle acceso, pero seré muy receloso, no porque se puedan robar la idea, ya se las estoy compartiendo! sino porque tiene algún que otro bug y, como les dije, uno es un poco vanidoso como developer
Para otro día queda el análisis particular de los operadores políticos más ferreos, los "megáfonos" que incitan a la tropa, son todo un tema que merece dicho capítulo aparte.
Si te gustó esta nota podés...

Escrito por Fabio Baccaglioni
Otros posts que podrían llegar a gustarte...
Comentarios
-
tucho235 dijo:
uffff... me paro y aplaudo el laburo.
Quien sabe como habrían sido los resultados de las elecciones sin estos tipos de ´intervenciones´ en las redes.
Hace un tiempo leí un post que decía que Trump había usado BigData para su campaña, analizaban unos pocos posts de los usuarios de fb y ya sabían clasificar los intereses de cada uno, juntaron como 250 millones de perfiles. Luego habían creado algunos perfiles en fb donde operaban a la masa votante, promocionaban posts y anuncios muy muy segmentados, a los q estaban a favor del aborto les decía algo de eso, tal vez la mitad de estos usuarios estaban en contra de acciones militares en el mundo y entonces a esos no les mostraba algo relacionado con la milicia, pero a otro tanto que estaba interesado si le mostraba. Fueron sembrando una ´idea´ de político que se interesa por tu interes y que te escucha. Esto se está yendo de las manos
si, efectivamente se hizo eso, aquí, en cambio, no hay tanto análisis, se busca más al furioso gritón, y si no te queda claro, te grito de nuevo es como en la calle, el patotero patoteando abarcando mucho. En el resultado final la gente le demuestra en el cuarto oscuro que no siempre piensa lo mismo que el gritón que hace ruido.
es como en la calle, el patotero patoteando abarcando mucho. En el resultado final la gente le demuestra en el cuarto oscuro que no siempre piensa lo mismo que el gritón que hace ruido.
Jorge-1987 dijo:
Felicitaciones man, buenisimo el laburo!
gracias!
-
Javier
 23/08/2017 - 12:27:56
23/08/2017 - 12:27:56
Hola Fabio. Se ve que le metiste bastante esfuerzo, la interfaz esta mucho mejor, y parece con muchas mas posibilidades que la v1 en lo que es recuperar y analizar los datos. Todo la automatización con un CRON es nuevo no? Digital Ocean?

Cuando leia pensaba en la cantidad de iteraciones que Google le hizo al algoritmo de PageRank, y como
es interminable el laburo que hacén ahí para evitar que se vuelva inservible, en Twitter hacen algo así? O funcionará masomenos igual a como lo hacía al principio y por eso es tan manipulable.
A mi me resulta interesante el proyecto, había revisado la v1 y tenía ganas de hacer algo con eso. Refactorizar? Crear algunas clases para organizar el código?
En esta versión incluiste algun framework, algo mas simple que Laravel, como Codeigniter o Fat-Free-Framework?
O armaste alguna estructura de clases como para encapsular el código de las tareas un poco y sea más cómodo para ir agregando cosas luego. Te interesa alguien que te de una mano con eso?
Me sumo a las felicitaciones! se ve barbaro.
-
Alberto Carrera (karrerovich)
23/08/2017 - 12:35:45
Buenísimo Fabio.
Horas libres bien empleadas.
Espero te sponsor den o que le puedas sacar $ a este muy buen laburo, aunque lo juzgues como desprolijo está a años luz de cualquier informe dibujado de consultora.
Felicitaciones.
-
Muy buena la aplicación. Me gusta mucho el aprovechamiento de las APIs.
Un par de pensamientos, espero que ayuden :
1.- Deberías (en la medida de lo posible) replicar estos análisis en campañas de publicidad On-Line; desconozco el mercado en ARG pero en EEUU o Europa; los resultados podrían monetizarse como parte final de la campaña en cuestión.
2.- Con un sitio principal que muestre "algunos" resultados de las campañas según tu procesamiento, podrías monetizar el acceso total al resultado.O al análisis de una particular campaña que el Cliente necesite.
3.- En Business Intelligence algunas empresas compran Extractores de Datos como el tuyo (parte de tu programación) para analizar la información "bajada"; es decir, Mineria de Datos sobre los tuits; hace unos meses probé uno. Estaba muy bueno, pero es caro para solo extraer datos de Twitter. :-( (NdeR: Me quede sin chiche para jugar el día del niño)
Nuevamente muy buena la idea y buen trabajo, al pensar algo asi.
-
Jose Rey dijo:
Muy buena la aplicación. Me gusta mucho el aprovechamiento de las APIs.
Un par de pensamientos, espero que ayuden :
1.- Deberías (en la medida de lo posible) replicar estos análisis en campañas de publicidad On-Line; desconozco el mercado en ARG pero en EEUU o Europa; los resultados podrían monetizarse como parte final de la campaña en cuestión.
2.- Con un sitio principal que muestre "algunos" resultados de las campañas según tu procesamiento, podrías monetizar el acceso total al resultado.O al análisis de una particular campaña que el Cliente necesite.
3.- En Business Intelligence algunas empresas compran Extractores de Datos como el tuyo (parte de tu programación) para analizar la información "bajada"; es decir, Mineria de Datos sobre los tuits; hace unos meses probé uno. Estaba muy bueno, pero es caro para solo extraer datos de Twitter. :-( (NdeR: Me quede sin chiche para jugar el día del niño)
Nuevamente muy buena la idea y buen trabajo, al pensar algo asi.
si, la idea es que a futuro sea fácil adaptarlo a cualquier necesidad, de hecho, no es muy difícil pero como lo hice rápido (y probando muchas ideas) no quedó muy parametrizable (los campos tienen nombrs definidos en vez de genéricos). Ponele que en una semana lo adapto a cualquier marca o escenario nuevo.
Obviamente no le dediqué tiempo a otro mercado porque ya con uno tenía bastante para hacer las pruebas y mejorar el código y funcionalidad.
Alberto Carrera (karrerovich) dijo:
Buenísimo Fabio.
Horas libres bien empleadas.
Espero te sponsor den o que le puedas sacar $ a este muy buen laburo, aunque lo juzgues como desprolijo está a años luz de cualquier informe dibujado de consultora.
Felicitaciones.
Igual lo estoy arreglando y mejorando todos los días, en unas semanas tal vez el código sea algo más decente y entendible.
Javier dijo:
Hola Fabio. Se ve que le metiste bastante esfuerzo, la interfaz esta mucho mejor, y parece con muchas mas posibilidades que la v1 en lo que es recuperar y analizar los datos. Todo la automatización con un CRON es nuevo no? Digital Ocean?
Cuando leia pensaba en la cantidad de iteraciones que Google le hizo al algoritmo de PageRank, y como
es interminable el laburo que hacén ahí para evitar que se vuelva inservible, en Twitter hacen algo así? O funcionará masomenos igual a como lo hacía al principio y por eso es tan manipulable.
A mi me resulta interesante el proyecto, había revisado la v1 y tenía ganas de hacer algo con eso. Refactorizar? Crear algunas clases para organizar el código?
En esta versión incluiste algun framework, algo mas simple que Laravel, como Codeigniter o Fat-Free-Framework?
O armaste alguna estructura de clases como para encapsular el código de las tareas un poco y sea más cómodo para ir agregando cosas luego. Te interesa alguien que te de una mano con eso?
Me sumo a las felicitaciones! se ve barbaro.
Como estaba empezando de cero ni usé un framework, tengo el mío propio para control de APIs, base de datos y usuario así que con eso bastaba. El código es muy sencillo igualmente y es fácil de entender, desprolijo es porque no hice buena separación de presentación-funcionalidad pero eso se hace en unos pocos días. Está todo bien definido.
Lo interesante es que Twitter no hace nada para frenar esto, mientras siga estando en boca de todos ¿Para qué frenarlo?
-
Martin C.
23/08/2017 - 15:46:03
Excelente laburo Fabio!, ya que estamos, el nombre "bothunter" me gusta mas...
-
Espectacular laburo, y justo pensaba eso que ponés de lo que es notable es que la militancia es más de utilizar los hashtags que la gente "real", la gente normal en tweeter hace consumo irónico del hashtag, nadie taggea en serio!
Bueno, y los publicitarios también lo usan mucho, pero en cualquier caso siempre es para "operar" no para compartir cosas realmente.
La pata sociológica de este análisis de datos duros sería ver qué tanto impacta este microclima "social" (soushial) en la sociedad real. Como es un microclima muy frecuentado por el periodismo parece ser significativo para formar opinion, pero siempre que hay bardo en tweeter pienso en el flaco levantando paredes en Jujuy y que todo esto le chupa un huevo (o de alguna manera muy indirecta lo impactará?).
Y finalmente tu análisis me dio miedito, si armaste esto vos imaginate lo que pueden hacer con el big data los dueños del boliche, ya deben estar escribiendo los primeros capítulos de la psicohistoria.

-
Fabio me encanto tu análisis y la manera en que decidiste el tiempo a crear algo así de útil. Te admiro mucho y espero que este trabajo te de los frutos que te mereces.
Me encararía saber como es que llegaste a este nivel de programación y utilización de frameworks, ¿estudiaste algo o todo autodidacta? otra pregunta (estudio esto, por eso me interesa, no es por otro fin), en que esta programado el front-end? (gráficos)
Disculpa que sea curioso pero te juro que la curiosidad me gana,
Un saludo y felicitaciones otra vez!

-
Miguel
23/08/2017 - 23:52:07
A medida que iba leyendo pensaba en machine learning, y al final vi que comentaste lo mismo. Es un caso que aplica perfecto. Hay cursos online sobre R o TensorFlow que quiza te interesen (yo estoy siguiendo un par en pluralsight bien para beginners y están piolas). Es una curva de aprendizaje alta pero vale la pena!
Felicitaciones por el laburo!
-
Miguel dijo:
A medida que iba leyendo pensaba en machine learning, y al final vi que comentaste lo mismo. Es un caso que aplica perfecto. Hay cursos online sobre R o TensorFlow que quiza te interesen (yo estoy siguiendo un par en pluralsight bien para beginners y están piolas). Es una curva de aprendizaje alta pero vale la pena!
Felicitaciones por el laburo!
me está matando la curva de aprendizaje, en este caso necesito a alguien que ya lo entienda para que me guíe porque no se ni qué estoy buscando cuando empiezo a leer
Ignacio Brasca dijo:
Fabio me encanto tu análisis y la manera en que decidiste el tiempo a crear algo así de útil. Te admiro mucho y espero que este trabajo te de los frutos que te mereces.
Me encararía saber como es que llegaste a este nivel de programación y utilización de frameworks, ¿estudiaste algo o todo autodidacta? otra pregunta (estudio esto, por eso me interesa, no es por otro fin), en que esta programado el front-end? (gráficos)
Disculpa que sea curioso pero te juro que la curiosidad me gana,
Un saludo y felicitaciones otra vez!
soy muy autodidacta, empecé así hace... mierda... 30 años! sí, luego intenté estudiar sistemas dos veces, lo que aprendí me sirvió mucho pero no a programar, eso lo aprendí por mi cuenta.
Para el frontend estoy usando bootstrap y chartjs para los gráficos, por detrás es PHP puro con algunas cosas que me armé a modo de framework personal pero evité usar uno porque cuando empecé con todo esto no tenía ni idea de a dónde iba ni cómo iba a hacerlo. No sería nada difícil migrarlo a uno sencillo.
Cattel dijo:
Espectacular laburo, y justo pensaba eso que ponés de lo que es notable es que la militancia es más de utilizar los hashtags que la gente "real", la gente normal en tweeter hace consumo irónico del hashtag, nadie taggea en serio!
Bueno, y los publicitarios también lo usan mucho, pero en cualquier caso siempre es para "operar" no para compartir cosas realmente.
La pata sociológica de este análisis de datos duros sería ver qué tanto impacta este microclima "social" (soushial) en la sociedad real. Como es un microclima muy frecuentado por el periodismo parece ser significativo para formar opinion, pero siempre que hay bardo en tweeter pienso en el flaco levantando paredes en Jujuy y que todo esto le chupa un huevo (o de alguna manera muy indirecta lo impactará?).
Y finalmente tu análisis me dio miedito, si armaste esto vos imaginate lo que pueden hacer con el big data los dueños del boliche, ya deben estar escribiendo los primeros capítulos de la psicohistoria.
el big data nunca considera a los individuos sino a la sumatoria, en mi opinión pierde el marco de referencia y no puede analizar correctamente la mala intención ni las operaciones políticas, es una mera opinión pero podría fundamentarla mejor
-
Martín
24/08/2017 - 09:56:05
Me da mucha curiosidad ver si estoy entre entre los usuarios y mas que nada ver como me catalogaste.
-
Pablo
24/08/2017 - 12:08:00
Ídolo!! Fabio conducción!!
Mi detector manual es hacer un comentario (señuelo) con juicio critico propio y original por fuera del maniqueo facebukeano y saltan todos los botsmilitantes a la yugular. No falla.
-
Martín dijo:
Me da mucha curiosidad ver si estoy entre entre los usuarios y mas que nada ver como me catalogaste.
pasame tu usuario y lo busco, pensá que mucho está catalogado "en masa" dependiendo la participación en ciertos tuiteos de ciertas cuentas "masivas" y militantes
Pablo dijo:
Ídolo!! Fabio conducción!!
Mi detector manual es hacer un comentario (señuelo) con juicio critico propio y original por fuera del maniqueo facebukeano y saltan todos los botsmilitantes a la yugular. No falla.
uso algo así para detectarlos, hay publicaciones clave que te recontra sirven para "marcar" en masa
timos dijo:
Ya te acusaron de fachx por estudiar la campaña de Santiago Maldonado?
nah, nadie, la gente normal no es tan burda
-
claudio
24/08/2017 - 23:11:13
cuando tuvimos machine learning en la universidad usamos un programa que se llamaba weka https://sourceforge.net/projects/weka/ tiene implementados varios algoritmos de clasificacion automatica
vos le pones las muestras, decis cuales son las "caracteristicas" que tiene q mirar y te las clasifica.
no era dificil. capaz te sirve.
-
Gus dijo:
Por casualidad tenes pensado liberar el código fuente?
aclaré en la nota que no, por el momento tengo pensado comercializarlo, siquerés pagar por acceso es baratito
claudio dijo:
cuando tuvimos machine learning en la universidad usamos un programa que se llamaba weka https://sourceforge.net/projects/weka/ tiene implementados varios algoritmos de clasificacion automatica
vos le pones las muestras, decis cuales son las "caracteristicas" que tiene q mirar y te las clasifica.
no era dificil. capaz te sirve.
gracias por el dato, trataré de leer alguna documentación, el site no es muy claro pero estimo que está ahí
-
Gus
25/08/2017 - 18:53:59
Fabio Baccaglioni dijo:
aclaré en la nota que no, por el momento tengo pensado comercializarlo, siquerés pagar por acceso es baratito
Se nota que leo a los saltos?
Es que si lo cobrás realmente lo vale, podés hacer un producto muy copado. Si necesitás una mano, te puedo ayudar con el código.
-
Swicher
27/08/2017 - 22:14:48
¿Que opinas de usar procesamiento de lenguaje natural para el machine learning? Por ejemplo, en http://www.nltk.org/book/ch06.html explican como clasificar texto con NLTK, que si bien esta en Python, en https://en.wikipedia.org/wiki/Outline_of_natural_language_processing#Natural_language_processing_tools también tenes otros programas de donde elegir.
Fabio Baccaglioni dijo:
Gus dijo:
Por casualidad tenes pensado liberar el código fuente?
aclaré en la nota que no, por el momento tengo pensado comercializarlo, siquerés pagar por acceso es baratito
claudio dijo:
cuando tuvimos machine learning en la universidad usamos un programa que se llamaba weka https://sourceforge.net/projects/weka/ tiene implementados varios algoritmos de clasificacion automatica
vos le pones las muestras, decis cuales son las "caracteristicas" que tiene q mirar y te las clasifica.
no era dificil. capaz te sirve.
gracias por el dato, trataré de leer alguna documentación, el site no es muy claro pero estimo que está ahí
Quizás te sirva lo de http://www.cs.waikato.ac.nz/ml/weka/documentation.html
-
Swicher dijo:
¿Que opinas de usar procesamiento de lenguaje natural para el machine learning? Por ejemplo, en http://www.nltk.org/book/ch06.html explican como clasificar texto con NLTK, que si bien esta en Python, en https://en.wikipedia.org/wiki/Outline_of_natural_language_processing#Natural_language_processing_tools también tenes otros programas de donde elegir.
Fabio Baccaglioni dijo:
Gus dijo:
Por casualidad tenes pensado liberar el código fuente?
aclaré en la nota que no, por el momento tengo pensado comercializarlo, siquerés pagar por acceso es baratito
claudio dijo:
cuando tuvimos machine learning en la universidad usamos un programa que se llamaba weka https://sourceforge.net/projects/weka/ tiene implementados varios algoritmos de clasificacion automatica
vos le pones las muestras, decis cuales son las "caracteristicas" que tiene q mirar y te las clasifica.
no era dificil. capaz te sirve.
gracias por el dato, trataré de leer alguna documentación, el site no es muy claro pero estimo que está ahí
Quizás te sirva lo de http://www.cs.waikato.ac.nz/ml/weka/documentation.html
todo eso está perfecto pero sigo sin poder comenzar sin algo que me guíe. Es como que te den un menú con todas las opciones pero no tengas idea por qué camino seguir porque son todos demasiado confusos, me hace falta un ejemplo concreto de cómo podría clasificarlos.
mi mayor problema es que no hay un patrón fácil de implementar, no es un sólo camino, me explico:
Por un lado tenés todos los tuits de una persona
Pero los tuits se dividen entre los propios y los RT hechos a terceros.
No sólo eso, su timeline está lleno de uno o de otros?
Pero aquí no termina la cosa, se suman patrones en cuánta gente sigue, cuántos los siguen, y quiénes, esto no tiene nada que ver con lo anterior (no se ve en el timeline).
El tercer grupo de información es desde el cliente de Twitter utilizado hasta la frecuencia de publicación, los hashtags que usan y varias combinaciones más posibles.
Por otra parte tengo la suerte de tener clasificados unos 50.000 usuarios como para comparar resultados en cualquiera de las variables posibles, por lo que el training set existe, lo que me falta es entender cómo se le ingresaría esto a un sistema de ML (para ordenar el input) y básicamente por donde empezar.
Como la verdadera solución a mi problema es... prácticamente toda una carrera nueva no tengo muchas posibilidades de implementarlo fácilmente...
-
una cierta cantidad de usuarios clave y uno ya tiene la muestra representativa
Muy lindos los gráficos, pero me creo están un poco sesgados.
-
Marcelo Rimbaud dijo:
una cierta cantidad de usuarios clave y uno ya tiene la muestra representativa
Muy lindos los gráficos, pero me creo están un poco sesgados.
ajá y tu evidencia de cesgo? acaso viste los datos duros? acaso te molestaste en analizarlos? nah, obvio que no, lo tuyo es el prejuicio que tenés hacia mi persona solamente por suerte no es un sistema que hago para vos.
por suerte no es un sistema que hago para vos.