24/06/2025 - 09:00:00 por Fabio Baccaglioni
- 2710 - 16 - En Informática
Una de las consecuencias de la batalla de las Inteligencias Artificiales por coleccionar toda la información suficiente antes de la "gran contaminación" es el ataque sistemático a sitios web colapsándolos.
La "gran contaminación" es, según mi propia definición 😁, el punto en que el contenido de Internet está tan sucio de contenido generado por AI que resulta imposible confiar en las fuentes. Poco a poco llegamos a un punto de "mugre" de contenido generativo que nos dejará sin fuentes escritas "sanas" salvo un par (¿como este blog?).
Aquí les cuento todas las cosas que hago para mitigar este ataque permanente de cientos de pequeñas empresas que pasan sus "Spiders" por el blog tratando de capturar hasta el último byte de información sin preocuparse por las consecuencias que generan.
No es mi primer posteo al respecto, pero cada tanto vale una actualización. Les voy a contar primero cómo es la "seguridad" del blog, no desde el punto de vista del hacking sino del tráfico.
Es interesante cómo evolucionó todo, en una época la mayor preocupación eran los bots que buscaban vulnerabilidades para infectar tu sitio y utilizar tu servidor para engaños, scams y envío de spam, ahora en cambio el peor enemigo son empresas "legítimas" con prácticas "ilegítimas".
La defensa
La primera barrera de defensa que tengo es Cloudflare, aquí expliqué cómo se usa para evitar consumo en exceso en el servidor.
Esta empresa ofrece un servicio gratuito que hace de contención del tráfico, le envía lo "repetido" y logra que tu servidor no se caiga a cada rato, una CDN con algunos extras como poder agregarle filtros y, además, con detección de unos cuantos bots de AI a los que les sirve una versión cacheada de tu sitio.
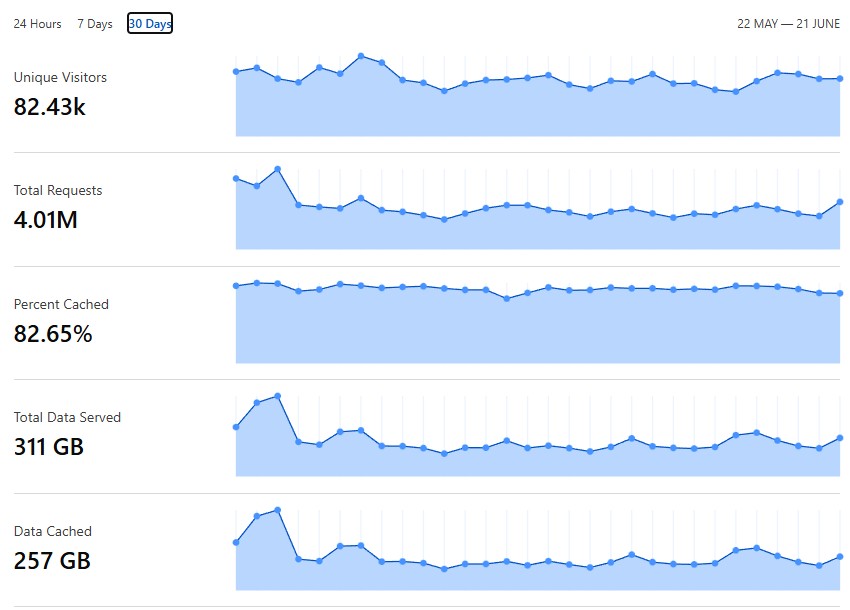
Aquí pueden ver como el blog recibió 4 millones de requests de diverso tipo en el último mes, el 82% fue cacheado así que pasó por Cloudflare solamente, el restante 18% vino directo al server. 257GB salieron de Cloudflare y no de mi hosting, bien, primer filtro.
Pero ese 18% no es fácil de manejar, suele tener una gran cantidad de requests que no apuntan a nada o que están mal formados, entre ese 18% también están los dos spiders más importantes: Google y Microsoft. Esos uno los tiene que dejar pasar si quiere aparecer en algún resultado de búsqueda, así que trato de evitar bloqueos.
En Cloudflare tengo configurada una lista de IPs de servidores que prácticamente han "atacado" mi blog, son de lo menos respetuoso que hay, también expliqué eso aquí.
Los nuevos parásitos
Hasta aquí todo lo normal, uno diría que con ese 18% restante se puede lidiar fácilmente, pero esta era de bots de AI extirpando hasta el último texto de tu sitio web tiene un costo mayor cuando empiezan a utilizar prácticas no tan santas.
La primera de ellas es omitir el "User Agent" de manera tal de simular un visitante normal, esto impide la mayor parte de los bloqueos ¿quién querría bloquear a sus propios visitantes legítimos? Simular uno es la clave.
Para ello contratan muchos VPN y crean pequeñas instancias de servidores, de esta manera simulan distintos usuarios de distintos países con un problema: mucho tráfico NO HUMANO sin identificarse como tal.
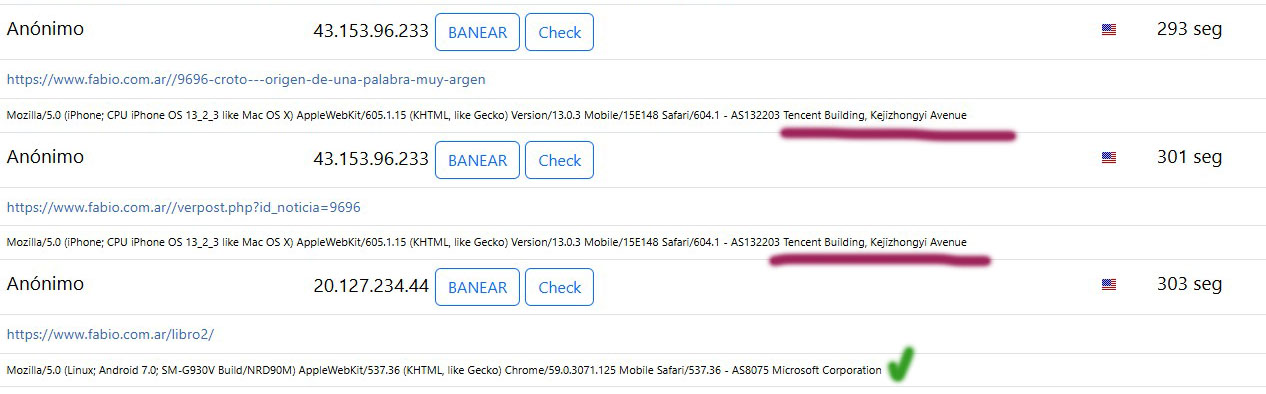
Si yo supiera que son bots podría identificarlos, mostrarles una versión cacheada del sitio y dejarlos pasar, creé una función para eso hace años y luego la publiqué en github. La mantengo actualizada.
Pero eso sería si jugaran honesto, la mayoría no lo hace, utilizando hasta el último VPS logran pasar cualquier defensa, es ahí cuando tuve que intervenir activamente. A diario bloqueo cientos de rangos de IP!
Este sería el trabajo más artesanal de todos, miro las sesiones activas entrando al blog, las logueo, identifico el proveedor de ese IP y ahí detecto a los típicos garcas:
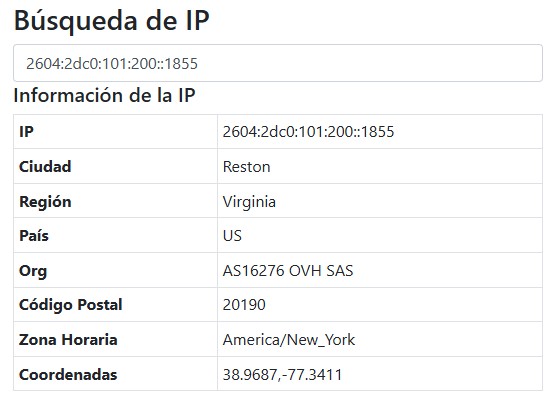
OVH, Digital Ocean, Hetzner, y todos los proveedores de VPS que te puedas imaginar, tengo que bloquearlos a todos. La única razón para que alguien acceda desde esos IPs a mi sitio es porque están haciéndolo artificialmente desde un robot, usarlos para crear una VPN tiene sentido, okey, pero esos son los menos (en dónde cuernos estaría prohibido mi blog? Ah, si, en empresas 😅).
El finde pasado me despaché con toda esta lista de bloqueos:
217.182.77.*
151.80.133.*
151.80.133.*
149.202.51.*
146.59.127.*
145.239.81.*
145.239.89.*
145.239.87.*
141.95.54.*
141.94.76.*
141.94.77.*
141.94.78.*
57.129.139.*
57.129.81.*
57.129.81.*
54.38.214.*
54.37.19.*
51.195.252.*
51.91.254.*
51.91.255.*
51.91.250.*
51.89.164.*
51.38.115.*
51.38.112.*
(el asterisco es para bloquear todo el rango)
El problema que generan es que hay miles de VPS, servidores privados virtuales, con rangos enormes de direcciones de IP que uno no puede bloquear, es una guerra desigual.
Los problemas que generan
En mi blog tengo todo bastante controlado, no sólo el código del Postrev es 100% mío, ese control total me permite crear mitigaciones que otros no pueden cuando dependen de un enlatado o de un soft mucho más complejo.
Además me permite analizar al detalle qué está sucediendo, miren mi bonita pantalla de estadísticas 😁
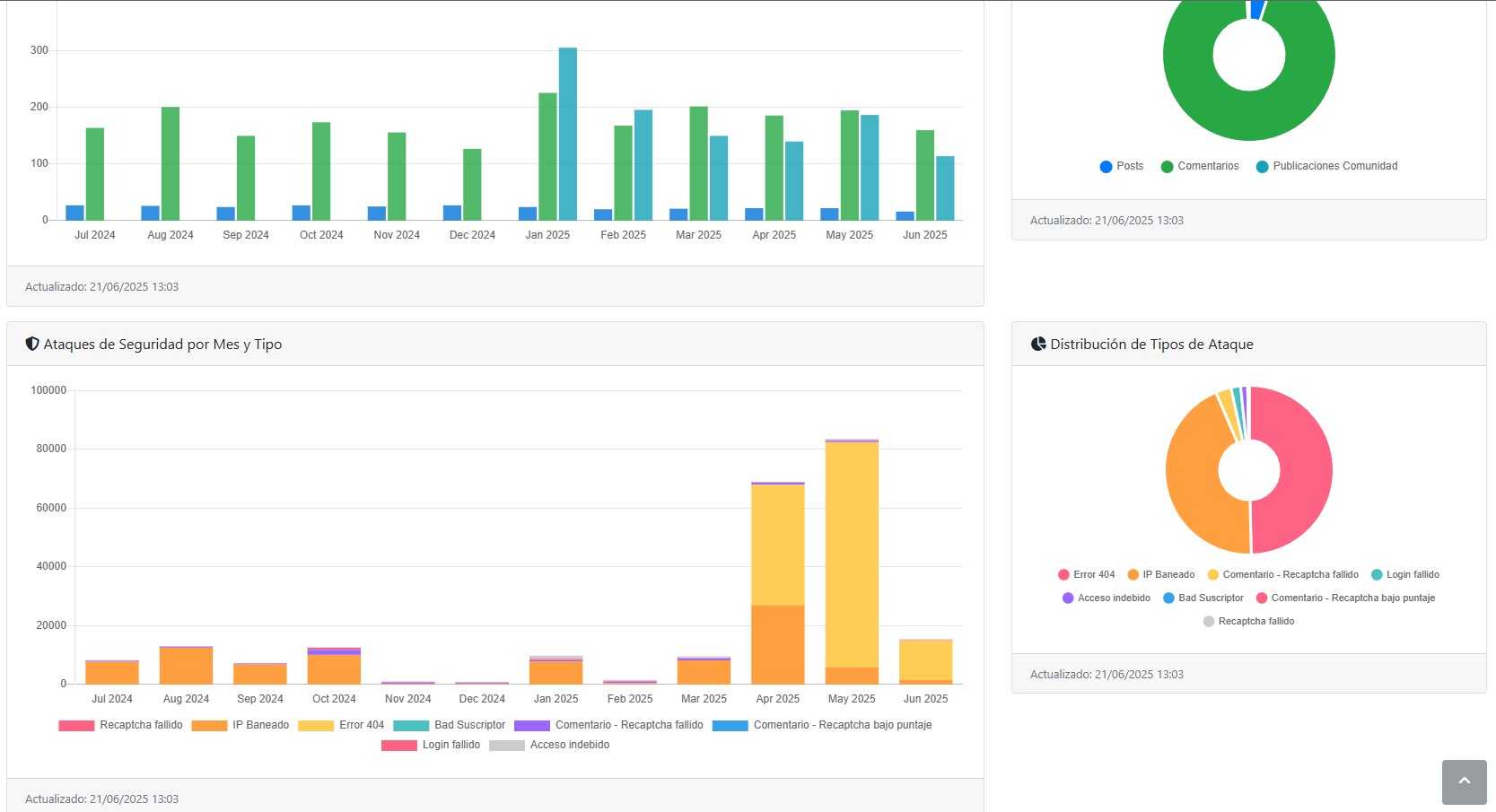
Puedo entender qué está pasando, quién lo genera y por qué, algo que si tenés, por ejemplo, Wordpress, no podrías y dependés de plugins como Wordfence que te bloquean info para poder venderte la versión Pro. Yo soy mi propia versión Pro.
Muchos clientes que conozco han tenido este problema, el server se les va al 100% de CPU en muchos momentos, el 90% del tiempo el problema es este, se les cae el sitio y le hechan la culpa al Wordpress o al proveedor, insisten en no entender aquello que no ven: las AI.
Si hace un par de años teníamos dos spiders (Google, Microsoft) ahora tenemos 30-40, es imposible que un servidor logre contener eso, no fueron pensados para ese tipo de tráfico masivo, menos los de una página web simple, pero tampoco las grandes como Wikipedia y tantos otros sitios de información libre que son sometidos a un ataque DDOS permanente.
El costo generado por eso es altísimo, las visitas no suben, la gente real es la misma de siempre o menos, sin embargo el costo de mantener el sitio web ha subido al doble o triple.
Se ha reemplazado el tráfico real por el automático, poco a poco vamos cumpliendo con la conspiranoia del Internet Muerto, pero pronto la haremos real, todo por no saber cómo mierda entrenar una AI sin romper todo el resto.
Todos están buscando reemplazar a Internet de alguna forma, el enemigo es la información libre, por eso hay que robarla antes de que otro la posea, es una carrera por coleccionar y catalogar todo antes de que sea demasiado tarde, quien posea todo el conocimiento y alimente a su máquina con él será el ganador (o eso creen).
Si te gustó esta nota podés...








 24/06/2025 - 11:00:03
24/06/2025 - 11:00:03
