Categoría: Programacion
Para programadores: Limpiar la base de datos
Estuve trabajando ayer y hoy con la limpieza de datos sin usar del RSS Reader y noté que había un exceso de material inútil ocupando megas y megas de datos, así que pensé en hacer un poco de limpieza y explicar algunos truquitos a usar antes de que se te llene la base de datos.
Como es de esperar, es un post típico para programadores así que lo dejo chiquito y pase el que quiera o esté interesado en el tema ![]() y si no entendés nada pero te interesa el tema, te puedo explicar en los comentarios
y si no entendés nada pero te interesa el tema, te puedo explicar en los comentarios ![]()
Importador de Feeds para el RSS Reader
Me lo habían pedido unos cuantos y ya está listo y funcionando. Gracias a código de Patricio Marín que me envió una muestra de cómo hacerlo, ya pude implementar la importación de los viejos feeds del Google Reader (si es que recuperaste esos datos antes de que cierre) en el lector de feeds de LinksDV.com
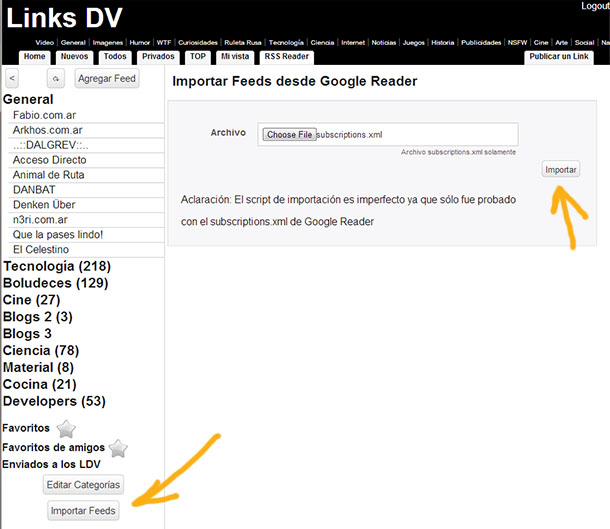
Así es, si todavía lo tenés podés importarlo, en los pocos días que lleva activo ya se sumaron unos 750 feeds nuevos al sistema, andábamos por los 300. Ante la importación notarán que muchos estan muertos, algo muy curioso, muchos feeds en sus colecciones estan fallecidos hace rato y nadie los borraba
Pues bien, eso más o menos se filtra, ahora bien, nada indica que funcione perfecto pero con las primeras pruebas, gracias a los datos de Miro Cardozo, Lucas Martín Treser y Leandro Rotela que me enviaron los suyos para probar.
Durante la semana que viene estaré trabajando en varias actualizaciones que van por detrás, no se ven, pero ayudan al mantenimiento general, como el eliminar los feeds ya muertos, pasar a modo "pasivo" a usuarios que se inscribieron y llenaron de feeds pero no lo usan nunca y quitar sus feeds de la actualización general.
Luego de ver el problema que tuvieron los de The Old Reader noto que es probable que el mayor problema para escalar es no sacarse a los no-usuarios de encima, es decir, los "testeadores compulsivos" que se suman a todo sitio para probar como es. Más de la mitad de los usuarios de mi RSS Reader son así y ocupan recursos al dope.
Esa parte del mantenimiento es un bardo, no es fácil, son muchos megabytes y son consultas pesadas a la base de datos, pero en términos generales se puede automatizar y, por ende, hacer el sistema escalable a más usuarios sin que falle la performance.
Bueno, los invito a sumarse y, de paso, integrarse a la pequeña comunidad de LinksDV.com que si no es por los RSS es por los Links, pero allí estamos
LDV RSS, el lector de feeds sigue creciendo
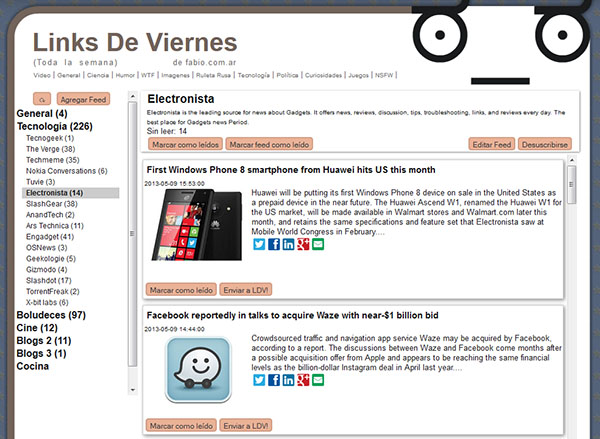
Gracias a los aportes de Tomás Perez que me ayuda con todo del debuggeo creo que podemos decir que la versión actual del lector de feeds de los Links de Viernes está funcionando de manera "aceptable".
Según Google queda hasta el 1° de Julio para migrar todos nuestros feeds a otros servicios, algunos optaron por feedly aunque no me convence la "necesidad" de una extensión para poder usarlo en el browser, así pues he migrado todos mis feeds a mi propio lector.
Durante los últimos días estuve trabajando bastante seguido, faltan muchas mejoras pero vamos de a poco, lo primero es lo principal, que se puedan agregar feeds a gusto y leer sus noticias, que el sistema los actualice constantemente, bueno, eso ya está en orden.
Durante los últimos días la mayoría de los arreglos fueron de maquillaje y de performance, esto último es medio complicado porque requiere tiempo de mi parte, pero aun así me animé a mudarme completamente para exigirle lo mismo que requiero de cualquier otro lector de feeds.
Quedan algunas modificaciones por hacer, esas que requieren entender bien JQuery que no es mi fuerte
Los invito una vez más a sumarse y probarlo al menos, no tiene nada muy especial, la única ventaja es que podemos compartir lo que nos gusta entre los enlaces de los Links de Viernes. A todo esto, en los próximos días mudaré el dominio a uno más corto que ya conseguí, así se vuelve más fácil de buscar, total no es un problema ya que la mayoría del tráfico es el de siempre, una redirección y listo
En Agosto los LDV cumplirían tres años ya, ya van más de 12.000 linkeos y 74.000 votos de los usuarios, súmense así somos más y conseguimos mejores links todos los días!
Geolocalizar números de IP

Hace un par de años, cuando intenté retomar mi carrera, en un TP (si, me tocó hacer un TP) quise aprovechar el tráfico de este site para armar el proyecto, básicamente había que hacer un sistema que tomase datos reales (las stats de un sitio son un lindo ejemplo de ello) y realizase varas operaciones. Eso servía como dato, pero lo que quería hacer en el proyecto involucraba detectar de qué país era cada número de IP de ustedes.
Lindo problema, nunca me había encontrado con la necesidad, pero hoy por hoy es algo más que necesario, desde campañas de publicidad hasta estadísticas más o menos fieles, la geolocalización te permite mostrar contenido preferencial para algún país, ocultarlo para otro o simplemente avisarle al usuario que hay algo especial si viene de X destino, algo que tan sólo con el número de IP no se puede obtener, hace falta algo más.
Ese algo más es lo que les explicaré en este post con la solución que hay dando vueltas y cómo implementarla en cualquier proyecto.
PHP: Detectar los spiders de los buscadores
Un poquito de programación rápida para comenzar la semana. El otro día me di cuenta que estaba creando sesiones a lo pavote para TODOS los que entraban al blog, algo normal para contabilizar de donde, cuantos activos y esas cosas que sirven a modo estadístico.
Con usuarios normales no es un problema, salvo ataques DDOS donde ese sería el último de mis problemas, jeje, pero con los bots de los buscadores... ah, eso sí que es un drama.
Cuando tu site recibe mucho tráfico o se actualiza seguido los spiders de los buscadores pasan también más seguido, así que te revisan cada rincón, aumenta el tráfico y las sesiones, lo que hice fue buscar una función (aquí en PHacks) para detectarlos y evitar tanto peso en el servidor, en PHP, es sencillo:
Tan sólo cuando entra pregunto si es un bot, ¿Por qué no guardar la lista en una DB? justamente porque lo que quiero eliminar son requests a la base de datos, con un hermoso y cochino if enorme podemos contener la mayoría de los bots que andan dando vueltas.
Contra toda la teoría de sistemas que te enseñan en la facultad, el "hardcodeo" es necesario cuando buscás performance, no está mal, es que hay que saber usarlo, en este caso es algo que se modifica rara vez y para aquellos que modificamos nuestro propio código, es más eficiente. En términos de eficiencia pura esto apenas consume un poquito más de memoria (unos bytes) en el script pero te quita una conexión TCP al servidor MySQL y la posible congestión de este, si la lista fuese más grande, bueno, sería otra historia.
Con esta pequeña función me ahorré un 90% de requests inútiles a la base de datos por parte de los buscadores cuando pasan a explorar el blog, a continuación les dejo una lista de muchos nombres posibles, yo sólo le cargué al mío los más comunes, Google y Bing, más otros tantos.
Update: Con el tiempo me armé mi propia función y, luego de diez años, ha acumulado una enorme cantidad de datos de buscadores y spiders varios, la pueden descargar libremente de mi GitHub
Un Feed Reader para los Links de Viernes
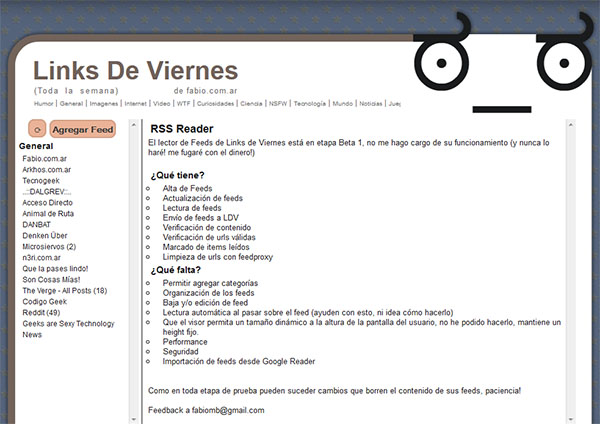
El lunes pasado llegué de vacaciones y me puse a programar cual adolescente con ideas, si, esas ideas que seguro ya tuvieron todos antes que vos, pero lo que estaba buscando era, como siempre pasa cuando programo, una solución a un problema mío que, por extensión, seguramente iba a beneficiar a otros.
Aun existiendo ofertas por todos lados como Feedly para reemplazar Google Reader (próximo a cerrar) quería tener mi propia solución dentro del site de Links de Viernes porque es el lugar lógico donde la gente pueda intercambiar enlaces interesantes. La cuestión es sencilla, yo siempre puedo disponer de mi propio código y no tengo que depender de la decisión caprichosa de un tercero, a la vez, por razones obvias, quien use mi sistema se encontrará igualmente desprotegido que si usase el de google, pero bueno, no puedo con todo tampoco
En mi caso tal vez pueda liberar el código algún día, primero tengo que hacerlo funcionar bien. A continuación les cuento qué hice, qué funciona y qué queda por delante (mucho).
Enumerando y actualizando posts en MySQL
El otro día me puse a contar posts de Ruleta Rusa y Links de Viernes, resulta que Google en ese afán de querer decirnos cómo debemos bloguear y no respetar un cuerno que a nosotros nos pasemos por el traste sus "reglas" optó por penalizar a cada site cuyos posts tengan el mismo nombre.
He aquí que con más de 400 posts que compartían el nombre tuve que hacer algo para renombrarlos y, al menos, enumerarlos.
No tenía ganas de hacer tablas temporales ni nada por el estilo, así que opté por una forma un tanto cochina que permite MySQL, primero hice una prueba para ver si más o menos podía hacerlo, como si uno estuviese programando en PHP pero esta vez dentro del MySQL, creamos una variable, la seteamos a cero y ésta será nuestro contador, es fácil:
SET @inc :=0;
Nótese el ; (punto y coma) para separar instrucciones, no se lo olviden porque no va a funcionar, el SET es una función separada del SELECT.
De esta manera @inc será una variable que incremente, su valor inicial será cero, ahora hagamos un SELECT de prueba, para ello en el primer campo agrego uno al contador, en el segudo muestro el título, tercero la noticia y cuarto uno que concatene el título, un guión y numeral (porque me place) y luego el número. Como verán usé CONCAT para armar el string final pero también CAST para pasar el número a char porque si no en algunos casos hacía cualquier cosa.
SELECT @inc := @inc +1 AS a, title, id_noticia, CONCAT( title, ' - #' ,CAST(@inc AS CHAR)) AS titulomejorado
FROM `posts`
WHERE title LIKE 'Links de Viernes%' and title <> 'Links de Viernes toda la semana'
ORDER BY time ASC
LIMIT 0 , 300
Busqué todos los LDV y de paso dejé afuera el post donde hablaba del nuevo sitio de los LDV, porque claro, no era lo mismo y me iba a quedar mal numerado.
Una vez que vi que estaba todo ok le agregué una columna temporal a la tabla, a veces hago esta grasada, sirve bastante, algunos hacen toda una tabla paralela y luego la renombran, preferí este cochino método. Obviamente antes de hacer algo así recomiendo hacer backup de la base, uno nunca sabe cuando se olvida de poner el WHERE en el UPDATE ![]()
Ahora con la idea encaminada me dispuse a actualizar ese nuevo campo, creo un VARCHAR del mismo tamaño que los títulos, con el nombre "titulomejorado" y me dispongo a rellenarlo con lo que corresponda:
SET @inc :=0;
UPDATE posts A
INNER JOIN (
SELECT @inc := @inc +1 AS a, title, id_noticia, CONCAT( title, ' - #' ,CAST(@inc AS CHAR)) AS titulomejorado
FROM `posts`
WHERE title LIKE 'Links de Viernes%' and title <> 'Links de Viernes toda la semana'
ORDER BY time ASC) X
ON X.id_noticia = A.id_noticia
SET A.titulomejorado = X.titulomejorado;
En este caso hago un join con la búsqueda anterior, la razón es simple, al ya tener todos los ID de noticia ya puedo actualizar uno por uno, funciona bien, es rápido y sólo afecto a las filas de los posts que me interesan, el resto ni se entera.
A muchos les cuesta un poco hacer querys dentro de querys pero donde le tomás la mano sale muy bien, el problema es cuando estás practicando y arruinás todo ![]()
Una vez ejecutado este UPDATE deja en el campo "titulomejorado" el nuevo título, podemos chequear que todo esté bien y ahí disponernos a usarlo definitivamente:
UPDATE posts
SET title = titulomejorado
WHERE titulomejorado IS NOT NULL; Obviamente la condición es importante una vez más, si no ponemos ese where dejando afuera todos los otros posts básicamente les vamos a borrar el título a todas las notas, algo que nos haría entrar en pánico ![]()
Luego de esto podemos borrar la columna temporal "titulomejorado", ahora todos los posts de Links de Viernes y Ruleta Rusa estan perfectamente numerados, por ahí hay otros posts más viejos que usaron otro título, pero esos no afectan en Google.
Para ver el tema de posts con títulos duplicados usen Webmaster Tools y ahí les dirá donde hay un problemita
Ah ¿se pensaban que ya no posteaba estas cosas en el blog? no se olviden de donde vengo mis muchachos ![]() , se aceptan correcciones e ideas más performantes a lo que sugiero, esto tan sólo me dio resultado
, se aceptan correcciones e ideas más performantes a lo que sugiero, esto tan sólo me dio resultado ![]()
Una ayudita con expresiones regulares
A ver, que a veces me toca a mí pedirles una ayudita a los lectores programadores.
Resulta que estoy trabajando con el código del blog para que las urls del mísmo no aparezcan duplicadas para Google, actualmente el buscador me voló del índice unos 3000 posts, como se imaginarán no me pone muy contento. Una de las posibles razones son los duplicados, no es algo intencional, sólo que desde que puse la posibilidad de que los posts se vean como: http://www.fabio.com.ar/5014 esto generó un problema
La url original era más bien fea: http://www.fabio.com.ar/verpost.php?id_noticia=5014 y por eso la idea fue acortarla a algo más sencillo.
El tema es que Google ve dos ahora, http://www.fabio.com.ar/verpost.php?id_noticia=5014 y http://www.fabio.com.ar/5014 para una misma nota, considera que estoy haciendo algo sucio duplicando contenidos aun cuando ambos son exactamente el mismo.
Para ello ahora hago un redirect en php y le envío un código 301, éste implica que es contenido "movido" y no duplicado. OK, hasta ahí bárbaro y si hacen click en una url larga y vieja los llevará a la corta simplificada.
Pero aquí tengo un problema, herencia del código viejo de mi blog, esta es la regla que ajusta la url:
RewriteRule ^([0-9_]+)$ verpost.php?id_noticia=$1&vieja=1 [L]
Hasta ahí todo perfecto, Apache se encarga de pasarle el parámetro si es que viene un numerito (el id del post) y se lo pasa a la vieja estructura.
El problema es cuando, por ejemplo, para emitir un mensaje de error (onda, escribiste una palabra spammera o te equivocaste el código de seguridad) le pasaba un parámetro, la url quedaría así:
http://www.fabio.com.ar/5014&mensaje=4
El problema con esto es que 5014&mensaje=4 no significa nada para esa expresión regular y directamente me lo desecha como error 404, un despropósito.
Por esto necesito cambiar:
RewriteRule ^([0-9_]+)$ verpost.php?id_noticia=$1&vieja=1 [L]
de manera tal que contemple no sólo el número de ID del post si no los parámetros extra como "mensaje" y lo pase a la vieja url, de esta manera yo sería un blogger muy feliz y, tal vez algún día, Google considere este blog digno nuevamente en su totalidad y no sólamente para 1800 posts ![]()
¿Mi problema? nunca entendí bien las expresiones regulares, así es, soy bastante burro con las malditas y no sabría como hacer para que me genere el parámetro $2 para mensaje, no es difícil, lo se, pero zoy ezpezial ![]() ¿me ayudan?
¿me ayudan?
Cuantas palabras tienen tus posts
 Hoy estaba pensando en esto ¿como cuernos cuento las palabras en mis posts? es que nunca me puse a hacerlo y de pronto me di cuenta que en MySQL no hay funciones para esto ¡hay que googlear! ya mismo, pásenme la googlera.
Hoy estaba pensando en esto ¿como cuernos cuento las palabras en mis posts? es que nunca me puse a hacerlo y de pronto me di cuenta que en MySQL no hay funciones para esto ¡hay que googlear! ya mismo, pásenme la googlera.
Así fue que encontré una forma, pero resulta que no sólo tengo que contar palabras si no que tengo que, primero, sacarle todo el HTML que yo le agrego a mis posts.
Así es, en el viejo y querido PostRev el código se agrega a mano lo que complica identificar una palabra y los números no me daban, así que a crear dos funciones, wordcount y strip_tags.
La cuestión también está en que una base de datos no es precisamente para hacer cuentas, esas debería hacerlas aparte, pero salvo que sean sumatorias estas eran cosas para hacer aparte. ¿como hacerlo y seguir dentro de MySQL? creando funciones y utlizándolas en la consulta.
Es un poco intensivo y recomiendo hacerlo solamente con una copia local de la base de datos, así si tienen que esperar no bloquean el blog durante un rato.
A continuación se las comento
Stardust, pequeño experimento
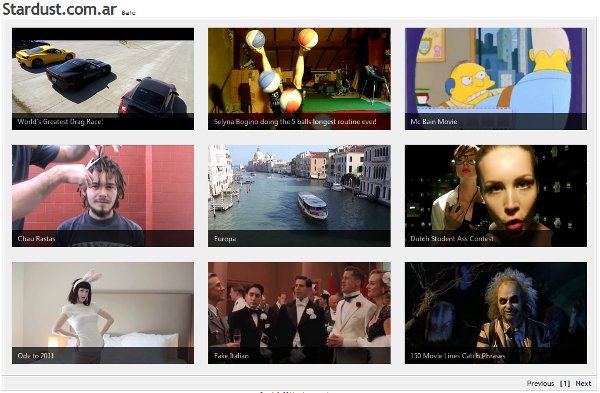
Estaba con necesidad de "programar algo", vieron, para el día del programador, así que publiqué ayer a la tarde un nuevo site, no es que pretenda actualizarlo muy seguido, pero era un experimento para crear una especie de "youtube" propio sin las restricciones impuestas en dicho servicio de video.
No es código pensado para difundir, apenas hay una base de datos de fondo para guardar los videos, no hay ni tags ni comentarios, sólo videos que me gustaron, bajo el mp4, lo preparo, lo subo, cito la fuente y lo alojo.
Más de una vez me encuentro con videos que me gustan y a la semana Youtube bajó por alguna regla idiota o le bloquean el poder distribuírlo o compartirlo entre sitios, todo para forzarnos a ver una cierta cantidad de publicidad o un canal de video en particular. O te censuran el audio porque en 10 minutos de video hay un sólo minuto de una canción, algo ridículo y que, al menos en la mayoría de los países del mundo (estoy incluye a los EEUU) es completamente legal porque entra en el esquema de "Fair use".
Bueno, pero no era sólo por cuestión de principios si no para ver si podía hacerlo, le dediqué unas 3-4 horitas algo espaciadas para ver si lo hacía de tal o cual manera, escribí un poco de código y me fue gustando la idea. Así publiqué Stardust.
Repito, la idea no es usarlo demasiado fuerte, ya tengo demasiados proyectos activos, Fabio.com.ar, Tecnogeek.com (mis dos blogs principales), Cake Division (mi agencia digital de publicidad), LinksDeViernes.com (comunidad online), Elección Argentina (wiki), PicPetz (imagenes de animales), No Al Canon (muy desactualizado blog de protesta), y un largo etcétera, la idea no es sumar más quilombo pero fue un divertido ejercicio de programación rápida "a las patadas" como me divierte hacer.
Así que disfrútenlo, cada tanto actualizaré videos y sumaré más, no hay nada ilegal, no se trata de un cuevana ni nada que contenga material "protegido", la idea es más bien boludeces y cosas entretenidas para ver.
Como siempre se aceptan sugerencias, ideas, aportes de código y críticas.