Ya les conté una vez cómo crear imágenes con AI en su propia PC usando ComfyUI, pero ahora vamos a redoblar la apuesta con... videos!
Así es, si te sorprende una vez más y creés que te quedaste en el pasado, tranquilo, aquí la idea es explicar justamente cómo se hace por si querés intentarlo en tu propia computadora sin tener que pagar el servicio extra de nadie.
La primer pregunta ¿Funciona? Pues sí, funciona y muy bien.
Hasta ahora los modelos y scripts que había visto para crear animación eran muy pesados y complejos. Desde mi PC que sólo tiene 6GB de VRAM (la memoria de video, del GPU), no podía ejecutarlos o requería demasiado trabajo.
Hace un par de días Stability.AI lanzó dos modelos para creación de video que logran mantener la coherencia entre un frame y el otro, el usual problema al querer crear videos a partir de imágenes únicas, y todo cambió rápidamente.
Muchas empresas ya estaban ofreciendo servicios para lograrlo, es decir, no es nuevo y se viene trabajando hace más de un año en esto, pero poder tenerlo en tu propio equipo es otro tema y que el resultado sea coherente y consistente ni les cuento.
Los creadores de ComfyUI, el sistema que uso para crear imágenes, actualizaron rápidamente agregando los módulos para poder crear video y aquí estamos.
Requerimientos
Al igual que para usar ComfyUI, ya que no cambia en absolutamente nada, necesitamos una PC con Windows/Linux/Mac que posea un procesador moderno y un GPU decente con toda la VRAM posible.
Todos los scripts de AI necesitan de memoria de video además de la RAM normal de la PC, la de video es la más importante. 8GB de VRAM en adelante lo recomendable, 24GB si se quiere hacer esto en serio (pro).
Python (nunca el último, chequear requerimientos de ComfyUI), Git (conocimientos mínimos para clonar un repositorio), suficiente espacio en disco (cada modelo pesa entre 6GB y 9GB) y mucha paciencia para el paso a paso.
El script de instalación se encarga de todo y las últimas versiones de ComfyUI tienen actualizador tanto del soft general como de los módulos de terceros.
Una vez instalado todo se ejecuta el script de arranque (run_nvidia.bat si usan placa de video) y se abre una ventana en el browser default.
Los workflows se cargan ahí, aquí más adelante les explico de dónde bajarlos.
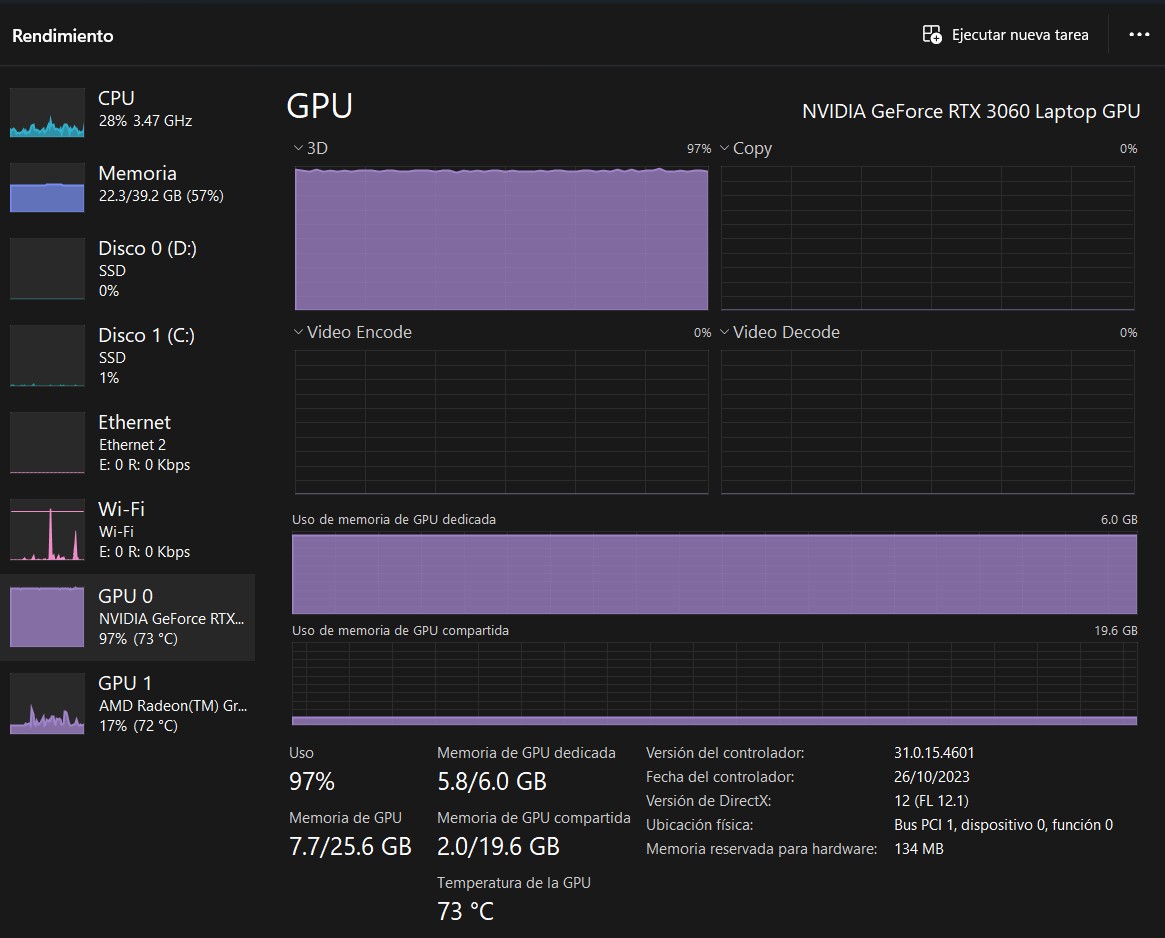
uso de recursos... el GPU quemándose
img2vid o txt2vid
Hay dos formas de crear animaciones, de una imagen existente o desde un prompt, en ambos casos el proceso es básicamente el mismo ya que de texto a imagen se crea sólo una, luego de esa se infiere el video. Lo mismo sucede con el más simple, img2vid, de una imagen se infiere el video.
Lo interesante de este proceso más simple es que puedo usar las creaciones previas, las cuales ya conozco y se que dan buen resultado, y animarlas. Hace un par de meses que me armé un catálogo con los checkpoints, los seeds y el resultado para tener una especie de catálogo (si alguno anda en esto me lo pide y le doy acceso, estaría bueno tener algo más organiziado con varios usuarios).
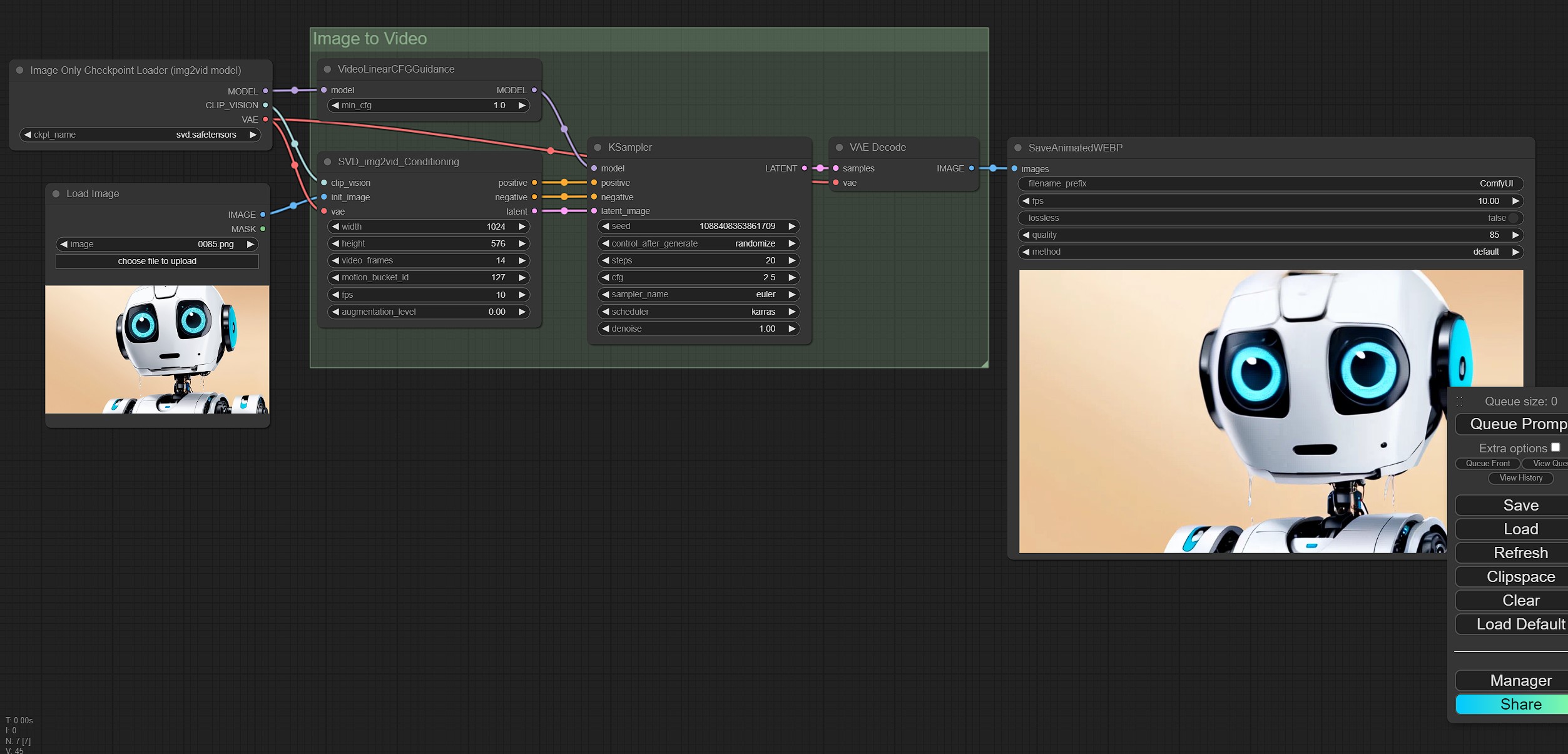
ComfyUI ofrece dos workflows, el primero de imagen a video utilizando la versión "simple" y el segundo de texto a video usando el modelo más "complejo", uno seteado a 14 frames y el otro a 25 frames.
Aquí la aclaración importante: memoria VRAM. Porque si bien Comfy hace un muy buen trabajo usando la RAM normal para importar el modelo, aquí se usa mucho la VRAM para crear los frames. Si quiero ir un poco más allá siempre me quedo corto de memoria.
Para darles un ejemplo: con 6GB de VRAM puedo crear clips de un segundo o lo que den esos 14 frames, si quiero más, me quedo sin memoria o tira error porque el modelo está pensado para esos 14 frames.
Podrán decir que 1 segundo es la nada misma y tendrán razón, es imposible para una notebook de este tamaño hacer más, pero es ideal para aprender y entender cómo funciona y los límites que estamos manejando.
No pretendo crear un film super largo, la idea es aprender y encontrarle las vueltas, expandir conocimiento y poder compartirlo. Tampoco mi GPU es muy potente, es una RTX 3060 pero de notebook, un poco más acalorada que la de una PC de escritorio normal.
Esto hace que procesar ese segundo me lleve dos minutos con el GPU al 100% calentando hasta los 85ºC, algo que no recomiendo sostener demasiado en el tiempo. Igualmente, si lo comparamos, es peor el uso de juegos como el Cities Skylines II donde tenés al GPU al mismo régimen durante horas.
El resultado se da en una resolución de 1024x576, todavía falta un tiempo para que veamos un 1920x1080, pero hasta hace un par de meses esto era ciencia ficción para la mayoría.
Dato: se puede usar con fotos propias existentes, probé con una y, si bien todavía falta para ser perfecto, me gusta por donde va:
Origen:
Resultados con ciertas variaciones:
Checkpoints y Workflows
Los checkpoints generados por Stable Diffusion son, como ya mencioné, para 14 y 25 frames, svd y svd_xt. (los links llevan a la descarga).
Con el de 14 van a poder crear cosas más largas, 14 cuadros por segundo es más parecido a un film de Animé que al celuloide de 24fps, si quieren apuntar a realismo y tienen buen GPU con VRAM para tirar al techo, apunten al de 25 y tendrán un resultado super realista.
Lo bueno de Comfy es que podemos crear lo que querramos con los modelos de siempre, así que podemos tranquilamente tomar una imagen de SD1.5 o de un JuggernautXL, para la creación del video da igual porque toma de fuente el resultado, el PNG final, no le importa el resto.
En los nuevos nodos de ComfyUI se puede confiugar lo siguiente:
video_frames: Cuantos frames vamos a generar en total
motion_bucket_id: Cuanto más grande el número más movimiento en el video final.
fps: Los cuadros por segundo.
augmentation level: La cantida de "ruido" que se añadirá a la imagen inicial, cuanto más sea el valor menos se corresponderá con el origen. Más alto y se moverá más también.
VideoLinearCFGGuidance: Al igual que el CFG de las imagenes, mejora el sampleo de los modelos .
Los workflows disponibles son muy sencillos, agregan nuevos nodos donde se procesa el video a partir de un input de imagen y, en el caso del txt2img se agrega la parte básica de creación de imágenes.
Los videos que ven aquí fueron todos generados con imágenes que previamente había creado y no me decepcionó para nada, notarán que varias las usé para posteos del blog!
Sólo un problema: los videos son creados en formato WEBP de video, el formato odiable de Google, por ende para convertirlos a MP4 hay que dar algunas vueltas. Lamentablemente ni ffmpeg ni VLC tienen soporte para este formato (algo rarísimo) así que pude convertirlos con el Adobe Media Encoder que lo soporta.
Los modelos de Stability son sólo para research, no son para uso comercial, todavía falta mucho como agregarle condicionamientos a la generación de video como ya se tiene con lo de imágenes, eso vendrá a futuro. Sus principales rivales son Runway y Pika Labs. Y si quieren algo con mucho más control pero todavía dentro del universo de Stable Diffusion van a tener que pasar a animateDiff , ahí no puedo ayudarlos porque es el universo de más de 12GB de VRAM 😋🤷♂️
Si están empezando a imaginar un film creado con esto, esperen un poco, cuando esté más pulido vamos a poder dar indicaciones y el resultado será más aproximado al esperado.
"Tampoco mi GPU es muy potente, es una RTX 3060 pero de notebook"
Yo desearia mucho tener una RTX 3060 . A mitad de año, con los precios, apenas pude comprarme una AMD RX 5500 XT 8GB. Espero que con esta GPU me permita realizar alguna animacion sin que explote todo
Bueeeeeno, vamos a experimentar y sacarle el jugo a la 3060 con 12 GB (gracias Mariana, gracias Fabio, por convencerme a tiempo).
Ya he visto un par de canales de música en YT que ponen una animación continuada hecha con IA. Supongo que lo que hacen es partir de una imagen, crear la secuencia, tomar el último frame y ponerlo como base de la secuencia siguiente. Es lo que voy a intentar hacer.
Ultimamente venía probando Flowframes para mejorar videos con stuttering y hacer "cámara lenta".









 29/11/2023 - 12:25:04
29/11/2023 - 12:25:04


