






Con http://phantomjs.org/ también podrías haberlo hecho en JS. Yo lo uso para generar png´s de las web, y funciona muy bien.
¿Que es el SM Day?
Scrapear Twitter sin consumir la API
Si algo está publicado en una web, se puede tomar, quiera o no el autor. Aun cuando te cierren o limiten una API, si es público, se puede obtener.
Así estaba yo ayer queriendo dejar de consumir tanto la API de Twitter cuando ejecutaba mi analizador de bots, estoy preparando una charla para el SM Day y quiero darla con data fresca y además un sistema mejorado (que publico en un git público, por si les interesa), pero me faltaba algo que le diese inteligencia al sistema para identificar bots más rápidamente.
La cuestión era sencilla, como humano basta con entrar al timeline de cualquier usuario de Twitter para darte cuenta si es un bot o no, hay patrones obvios que por más dedicación al spam que tengan no pueden evitar, de hecho, así es como funcionan la mayoría de los sistemas anti spam.
Por cada bot que identifico leo sus followers y followings, esta nueva lista de usuarios puede tener bots o gente común, si tenía de pronto 100 usuarios nuevos ¿Cómo podría identificar rápidamente si son potencialmente bots? si por cada uno vuelvo a consultar la API esto me dejaría sin API calls muy pronto, pero Twitter no te bloquea si simplemente entrás a la web de cada usuario.
Así pues ¿Podría identificar el texto en cada tuit publicado en su página sin tener que hacer una consulta a la API? Si, "scrapeando" la web de twitter...
Como siempre programo estas cosas en PHP porque me resulta muy fácil para hacer las cosas rápido, sé que en Python sería ideal y tiene más herramientas para esto, pero con PHP sobra, además lo uso desde un servidor local por lo que vuela.
Lo primero que hay que hacer para obtener el contenido es utilizar cURL, es bastante simple:
$ch = curl_init("https://twitter.com/fabiomb");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$output = curl_exec($ch);
curl_close($ch);
La consulta cURL se puede hacer más compleja con más opciones también, $output tendra literalmente todo el codigo HTML de la página en cuestión, en este caso es mi perfil de Twitter.
Ahora hay que parsear este contenido pero antes tenemos que meterlo en algo que sea fácilmente reconocible, una página web es un documento xml pero nunca está bien armado, ya he usado para otros scrapers SimpleXML y fue un dolor de cabeza por esto.
La opción es cargarlo como un documento DOM y avisarle que no nos tire dos millones de Warnings que seguro aparecerán porque aun siendo Twitter seguro algún que otro error en la formación del html hay.
$document = new DOMDocument;
libxml_use_internal_errors(true);
$document->loadHTML($output);
Con esto tenemos cargada toda la página web en un documento DOM ahora nos queda parsearlo hasta encontrar el lugar específico donde está el contenido de los tuits (mi objetivo)
En la web de Twitter la cosa varía de vez en cuando así que el HTML que debemos identificar probablemente no sea el mismo de un día para el otro. Siempre que armen un scrapper recuerden testearlo varias veces antes de mandarlo a robar toda una web, es imposible que siempre funcione.
Por ejemplo así es la parte en la que aparece el contenido de cada tuit:
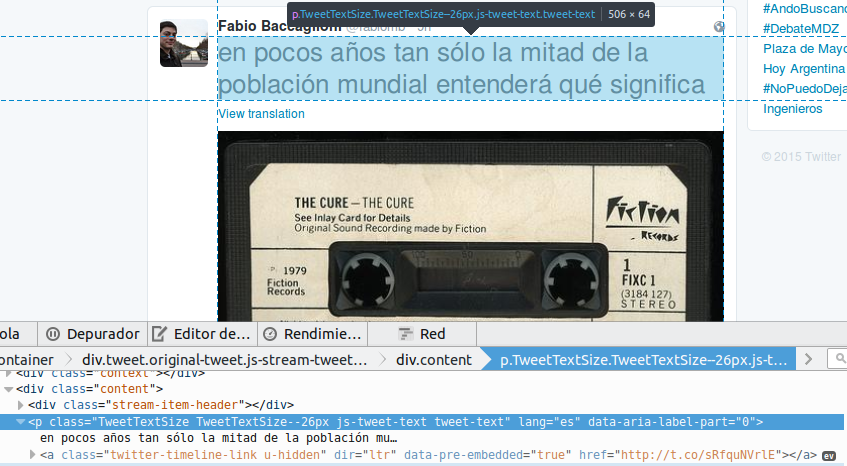
Lo que me interesa es:
TweetTextSize TweetTextSize--26px js-tweet-text tweet-text
El TweetTextSize obviamente puede cambiar, eso depende de muchos factores del CSS de Twitter asi que siempre chequeen en que valor está antes de empezar.
Yo se que ahí adentro, en ese P, está el contenido de texto, para recorrer el DOM Document utilizamos DOMXPath:
$xpath = new DOMXPath($document);
$tweets = $xpath->query("//p[@class='TweetTextSize TweetTextSize--26px
js-tweet-text tweet-text']");
Ahora $tweets tendrá un array con todas las coincidencias y lo que estaba dentro de ese P, lo podemos imprimir:
foreach ($tweets as $tweet) {
echo "".$tweet->nodeValue."
";
}
Y así de simple, ahora tenemos el contenido y nos costó cero API calls, luego éstas las podemos utilizar para identificar otros valores como obtener la lista completa de followers y data más sensible que sí debería tener ciertos límites.
En otra época Twitter tenía abierta la data del timeline de cada usuario, muy cómodo para cualquier programador ya que no necesitaba consumir la API para consultas boludas, lamentablemente Twitter tiene una política anti-programador que va creciendo, la de "programá esto para mí hasta que yo lance la misma funcionalidad y te prohiba existir", típica de los jardines vallados.
Pero, por suerte para nosotros, no pueden hacer lo mismo con el consumo web.
Consideraciones a tener en cuenta: si le revientan la web a cualquiera con miles de consultas por segundo se llama "DOS", si, una denegación de servicio, no sean animalitos y eviten que bloqueen tu IP desde su router, hagan de a tandas, como un spider de buscador cuando pasa por tu sitio, Google a veces es medio animalito y te tira 100 querys por segundo en tu blogcito y vos llorás, bueno, no se lo hagan a los demás.
Para los creadores de sitios simple, todo lo que publicamos es público, valga la redundancia, por eso es mejor apegarse a la Creative Commons, no me molesta que lo tomes, pero al menos decí de donde
Y para los que, como yo, tienen una necesidad particular para armar un estudio, bueno, esto nos viene perfecto.
Mi fuente para hacer esto fue Neel Seomani y mi post es una reversión del suyo
Si te gustó esta nota podés...

Categoría: Programación
Etiquetas: api dom document html php programación scrap scrapear en php scrapper twitter web
Otros posts que podrían llegar a gustarte...
Comentarios
-
dieguitofernandez dijo:
Con http://phantomjs.org/ también podrías haberlo hecho en JS. Yo lo uso para generar png´s de las web, y funciona muy bien.
¿Que es el SM Day?
pero PhantomJS no lo podés tirar en un servidor de 10 pé, en cambio cualquier cosa que hagas en PHP sí, es una cuestión pragmática.
también lo usé para crear pngs de páginas pero es recontra ineficiente en el uso de recursos a veces.
El SM Day es el Social Media Day http://smday.com.ar/ el 14 de Julio
-
Para mejorar el sistema se puede usar una caché de una cierta cantidad de requests realizadas, por ejemplo, LRU.
Dependiendo del firmware del router será más o menos sencillo resetear la conexión WAN desde el script, pero se puede. Incluso hay servicios que te brindan IPs para que uses de proxy y no te bloqueen.
No sé cómo está implementada SimpleXML pero en estos casos donde hay que parsear muchos documentos (aunque se ejecuten en un server los recursos no son infinitos ) mejora la performance si la librería está hecha en C o C++.
) mejora la performance si la librería está hecha en C o C++.
Me interesa el tema por lo que trataré de seguirlo
-
Fabio Baccaglioni dijo:
dieguitofernandez dijo:
Con http://phantomjs.org/ también podrías haberlo hecho en JS. Yo lo uso para generar png´s de las web, y funciona muy bien.
¿Que es el SM Day?
pero PhantomJS no lo podés tirar en un servidor de 10 pé, en cambio cualquier cosa que hagas en PHP sí, es una cuestión pragmática.
también lo usé para crear pngs de páginas pero es recontra ineficiente en el uso de recursos a veces.
El SM Day es el Social Media Day http://smday.com.ar/ el 14 de Julio
PhantomJS es muy lento, para scrapping usando JS lo mejor es combinar los módulos request para obtener el HTML de la página y Cheerio para poder usar los métodos de jQuery para obtener los datos desde el HTML.
Igual es cierto que JS no lo podés usar en cualquier servidor como PHP.


-
Mauro Daino dijo:
por ahí te conviene apuntar a https://mobile.twitter.com/fabiomb/tweets

si, pero es lo mismo , tengo que scrapear y parsear eso, son otros tags eso sí
-
Social Media Day IMHO los mismos vende-humo que los vendedores de autos y los de Amway/Herbal Life.
------
Muy lindo post, algun dia hare algo web, mientras tanto me divierto haciendo demonios...

-
Claro SM day... pero cuando te dije de mandarte a una TED me dijiste que no
 jajaja
jajaja
Muy copado el post! aunque yo PHP cero, se entiende igual
Abrazo!

-
pitufo loco dijo:
Un sitio puede llegar a generar dinamicamente los ids del html, para evitar el scrapping?
el scrapping sólo lo puede evitar con una sesión en particular para cada usuario y bloqueando excesos de requests, pero básicamente todo browser lo que está haciendo es esto mismo, solicita la página para renderizarla.
-
Fernando
 17/06/2015 - 20:00:50
17/06/2015 - 20:00:50
Fabio: N proxies Tor corriendo localmente + un HAProxy que haga loadbalancing sobre los N TOR. A tus scripts en PHP les indicas que usen el HAProxy y tenés N ip´s posibles para pegarle más rápido y sin peligro de que te corten el chorro!