





No olvides agregarlo a la sección sitios del blog y ponele algún nombre al proyecto 😃
Ahora voy a poder volver al habito de leer blogs, me quedó una lista vieja de blogs desactualizados hace más de 10 años.
Creando un buscador de blogs

Está Google, está Bing y hasta DuckDuckGo así que crear un buscador nuevo es un total despropósito, aun así quiero hacerlo ¿Por qué? Porque no quiero buscar entre los miles de sitios basura SEO y publicidad, quiero buscar entre los sitios que leo y leería.
Esto significa, autores reales, contenido creado por humanos y no por una AI, contenidos que se preocupan por el lector en vez de los buscadores y el SEO, donde la publicidad no sea lo prioritario sino comunicar cosas, ideas, aunque sean pensamientos varios. Un buscador de blogs.
Seguro ya existe alguno dando vueltas por ahí, pero decidí aprender a hacerlo yo mismo y... tan mal no me fue!
Creando un buscador que funcione
Habiendo aprendido bastante con el buscador dentro de este mismo blog era obvio que el Full Text Search de MySQL no sirve para nada, sólo para lo básico, así que para crear un buscador tenía que apelar a algo más "potente" y eso significaba salir de lo que conocía.
Tengo un servidor relativamente grande para este tipo de proyectos, con mucha RAM y discos rígidos viejos, pero vamos, no hacía falta mucho, no espero tráfico, sino un lugar donde encontrar lo que me interesa y donde algunos pocos puedan entrar si les interesa.
Lo primero que hice fue preguntarle a varios modelos LLM qué infraestructura de software me convenía y todos más o menos concluyeron en lo mismo:
Elastic Search
Como almacenamiento y buscador usar ElasticSearch o cualquiera semejante, si bien puede sonar "overkill" era ideal porque es mejor para realizar las búsquedas e indexar, si bien consume bastante RAM por estar hecho en JAVA es muy eficiente para lo que hace y mil veces más rápido y efectivo que usar MySQL/MariaDB para la tarea.
Así que el almacenamiento del buscador estaría dividido en dos, por un lado lo que se busca en ElasticSearch y por otro lado lo administrativo en una DB normal con MySQL.
Elastic es muy rápido, también sé que es problemático a la hora de escalar y tal vez necesite ayuda para ese entonces, pero por lo pronto prefiero mantener un índice pequeño, no soy una mega corporación.
El Spider
Para llenar el índice del buscador iba a necesitar un proceso bien hecho, en realidad más de uno, pero no en PHP que suele cortar la ejecución, necesitaba algo más resistente y sólido, Python es lo ideal.
En este sentido creé tres scripts, uno para validar sitios, otro para escanear el feed RSS y otro distinto para explorar los Sitemaps de cada sitio, el de feeds es ideal para lo inmediato y se ejecutaría más seguido, el del sitemap una vez a la semana en tandas de 1000 artículos para guardar lo histórico de cada sitio poniéndoles un límite, es decir, no puedo almacenarlo todo así que cada sitio tiene un límite máximo salvo que el autor me pida que ingrese todo (eso lo veré más adelante), el único sitio que puedo indexar completo es el mío propio, claro.
Logré hacerlo funcionar en mi servidor así que está indexando poco a poco lo que le indico y lo hace con mucha paciencia, un link por vez, nada de bombardear servidores.
Igualmente he tenido problemas con algunos sitios, muchos no tienen sitemap, así que sólo puedo obtener el feed de los últimos posteos (no es un spider que recorre todo el sitio, sólo los links que aporten sus feeds y sitemap) y en algunos casos hay bloqueos para evitar spiders así que no se puede obtener nada de nada 🤷 por ahora vengo bien con unos 50 sitios.
La interfaz
Obviamente divivida en dos partes, admin y pública, la pública es fácil porque es un buscador, no tiene muchos misterios.
Le puse sí la posibilidad de seleccionar entre inglés y español y que filtre por fecha los contenidos, algo que uso mucho en Google.
Tiene, además, varias opciones para condimentar la búsqueda como usualmente debe tener todo buscador.
Además le puse un menú para sugerir sitios, por si me quieren pasar alguno y nada más.
Por otra parte el admin, donde administro el sitio y disparo escaneos, los mismos los hice evitando el uso de exec, simplemente dejan un aviso al spider y cada minuto se analiza si hay un pedido nuevo.
Por lo pronto no tiene cosas muy complejas y lo quiero mantener simple en ese sentido.
La interfaz está toda hecha en PHP/MySQL separada del índice de Elastic y del spider en Python, así que sí, parece un mix incompatible, pero quise usar la herramienta adecuada para cada actividad y es lo correcto.
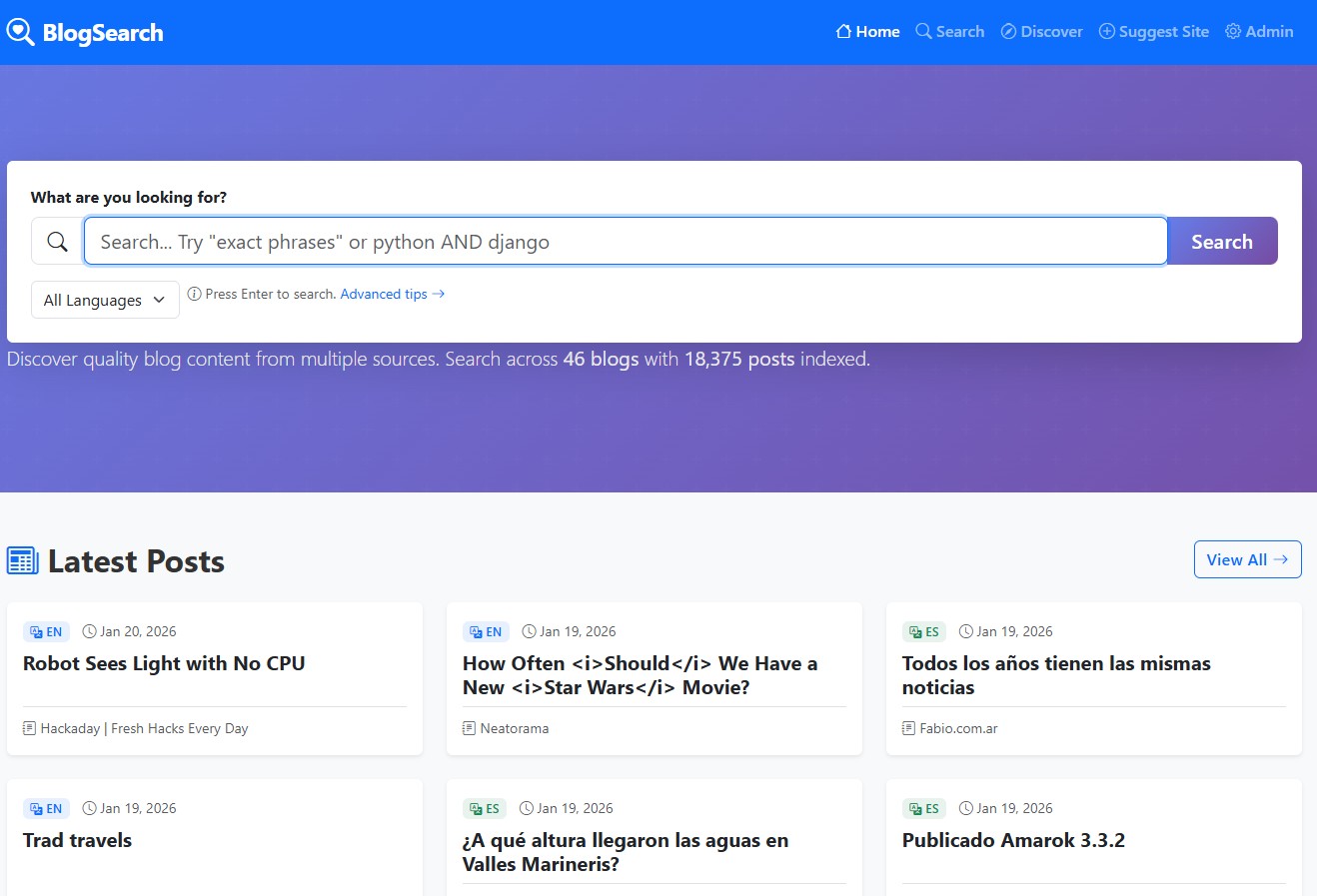
Qué indexar
Aquí el gran tema ¿Qué va a indexar en un buscador sin usuarios? Pues bien, es un buscador para nardos como nosotros.
Hace mucho tiempo que no encuentro nada en un buscador tradicional, los resultados o son patrocinados o generados por AI, se prioriza el SEO y no el contenido y no hay nada curado: todo entra y lo interesante desaparece.
Por eso aquí decido YO qué contenido entra, primero cargué unos 20 sitios que tengo en mis bookmarks, pero quiero ir sumando más. No quiero sitios de noticias que postean 50 cosas al día, quiero contenido que valga la pena encontrar.
La idea es mostrar en la portada del buscador un feed con lo último indexado ordenado por fecha, como un lector de feeds pero de todos los sitios que son escaneados.
Desde ya que algún autor puede negarse, lo bueno es que con sólo pedírmelo lo borro, nadie está obligado, no soy como los otros buscadores que se cagan en lo que vos querés, jeje.
También puede que alguien quiera que sume su blog hecho 100% con AI de notas SEO friendly y lo mande dulcemente a cagar: ya existe Google para eso, no rompan.
¿Y si estoy equivocado y entra uno trucho? Me avisan, que soy bastante contactable, che!
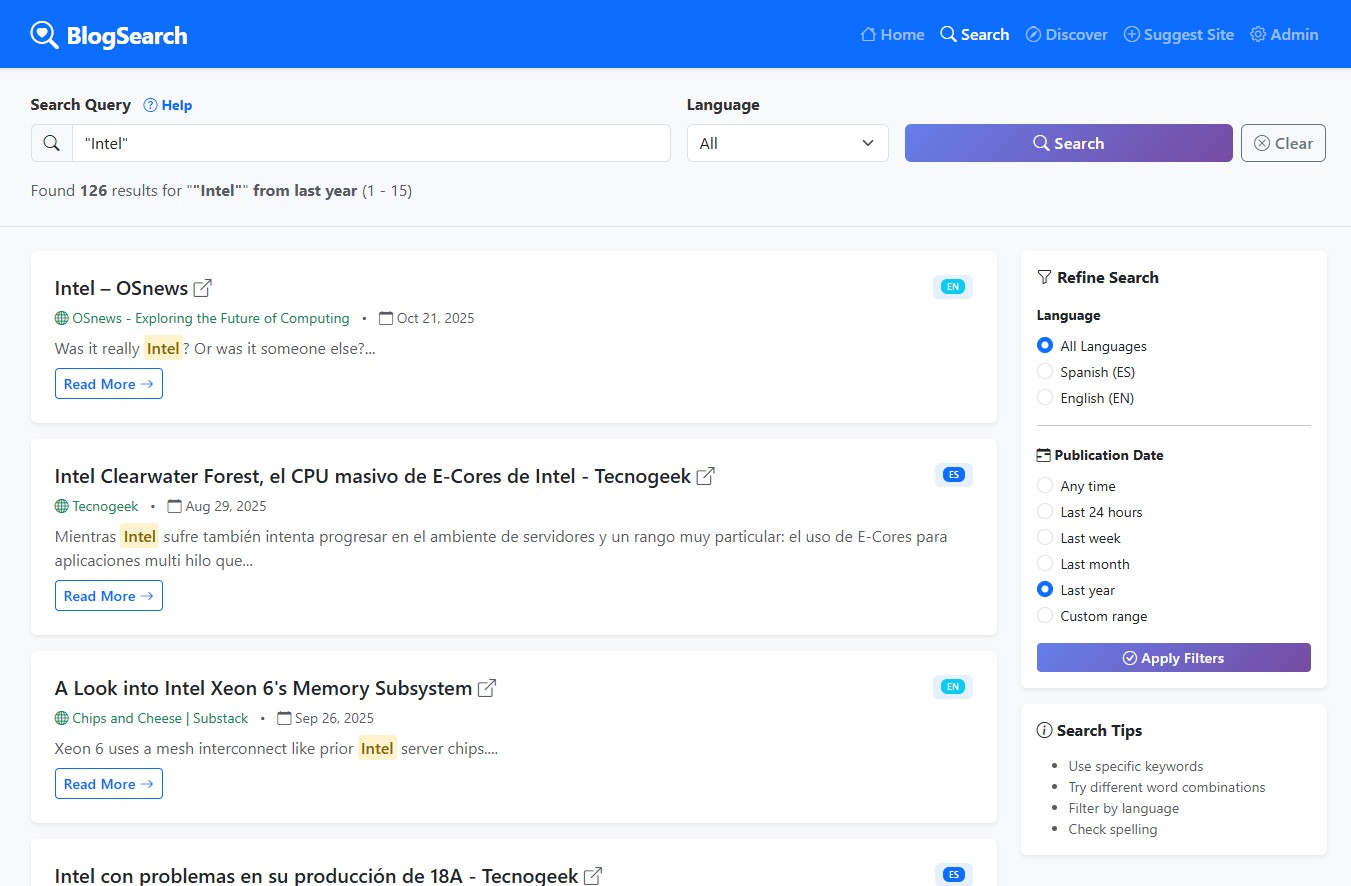
Desde ya que no es un proyecto comercial, es totalmente experimental y con el fin de encontrar cosas que valgan la pena leer de gente más interesante que bots, cosas de humanos para humanos.
¿Qué sitios me sugieren? Déjenme sus listitas en los comentarios así los voy indexando, sólo sitios de autores independientes, nada de empresas que viven de publicidad, ellos ya tienen sus visitas por SEO, no me interesan.
Pueden ingresar al buscador aquí, apenas tiene 46 sitios indexados y unos 20.000 artículos, obviamente el sitio más indexado es el mío porque lo usé de testing 😁, pero si me dan una ayudita puedo aumentar más la cantidad y variedad.
PS: está en inglés, pero ya lo voy a traducir al español también, la interfaz no tiene mucho cariño todavía como para estar usable, falta cachear consultas, ponerle filtros anti spam/anti AI, y todas esas cosas.
Si te gustó esta nota podés...

Categoría: Programación
Etiquetas: anti seo blog blogs buscador desarrollo elastic search elasticsearch internet programación python search engine seo sitios web
Otros posts que podrían llegar a gustarte...
Comentarios
-
Hugo
 20/01/2026 - 09:42:28
20/01/2026 - 09:42:28
Genial el proyecto!!
Unos pocos aportes
https://culturizando.com/
https://chequeado.com/
https://historiasdelahistoria.com/
https://lavozdelmuro.net/
https://cnho.wordpress.com/
https://lamentiraestaahifuera.com/
https://geeksroom.com/
https://www.elblogsalmon.com/
-
Proyecto interesante, mi sitio no es nada del otro mundo, no lo actualizo hace tiempo, no soy experto en nada pero siguiendo tutoriales aprendí a instalar LAMP, a instalar Wordpress, a comprar un dominio, lo tuve alojado en mi casa, ahora también aprendí a usar un hosting de pago...aprendiendo. Me gusta hacer rendir lo que tengo, que son computadoras viejas, así que tengo algunos artículos sobre Puppy Linux. Así que aporto mi sitio:
https://unfrionegro.net
Tu blog es uno de los pocos que van quedando, y está muy bueno.
Saludos
-
Uh, se ve bueno y con un gran trabajo detrás. Ya estuve echándole un ojo y la mayoría de los blogs ya los sigo, pero los resultados bastante precisos.
Tengo una duda. Si sigue los feeds RSS, eso significa que se atascará en los que solo permiten el excerpt y los que solo generan el de los últimos 10 post? o se basa en el sitemap para hacer un escaneo completo del sitio?
Te dejo un blog que tal vez ya sigas, pero es mi favorito de probablemente decadas XD
https://www.teknoplof.com
-
Muy buena iniciativa y el detalle del proceso creativo.
Paso el nuestro para sumarlo:
https://managementestrategico.blogspot.com/.
Gracias!
-
Tulio Serpio
20/01/2026 - 11:01:58
Busco cualquier cosa y sale primero fabio.com.ar.... Estás copiando a las grandes corporaciones!!!!!
por algo se empieza, supongo
-
Germán
20/01/2026 - 11:15:08
https://viajarleyendo451.blogspot.com/
https://www.hugozapata.com.ar/
https://www.sirchandler.com.ar/
Saludos!
-
Maravilloso!
Justo venia la comunidad a hacer una pregunta mucho mas puntual y me encontré con el post. Gracias!
-
Interesante, desde la muerte de Google Reader, un poco que abandone los RSS y por ende los blogs. Voy a revisar para ver si tengo alguno que aún siga funcionando y este interesante.
Un detalle, en el admin te quedó "Default credentials: admin / admin123", obviamente lo probé y no funciona.

-
Buenísimo. En el post pasado un usuario puso en comentarios una url que chequea post reales, mejor dicho, va actualizando los comentarios de blogs hechos por Humanos. Lo estuve chusmeando y está bueno, podes sacar algo de material de ahí: https://blogblog.es
-
diego
20/01/2026 - 19:11:57
blog nuevo sobre tecnología retro. te va a gustar:
https://retrotechycafe.wordpress.com/
-
Saturno
20/01/2026 - 22:08:57
Genial proyecto, te sumo otro blog:bahiasinfondo.blogspot.com/
Acerca de historias y lugares de la Patagonia
-
Se podrían indexar foros también? ya que son otro espécimen en extinción pero que a los nardos nos gusta surfearlos....
-
Fabio, esto te puede interesar:
https://www.blogsareback.com/
Blogs que tengo en mi RSS (aparte del tuyo):
https://www.microsiervos.com/
https://www.elladodelmal.com/
https://changlonet.com/blog/
https://www.smbc-comics.com/
-
Excelente! Acabo de buscar "enano cirqueros motociclistas" salió un post tuyo del 2003 con un enanito tocandose mirando a "Blancanieves" . 10/10
-
Juu, logré revivir esta cuenta!
Fabio, fijate si te interesa Marginalia, en HN siempre la gente le tira flores. El tipo se armó un buscador similar, de blogs, de sitios old-school, y también suele escribir en su blog sobre qué está implementando para mejorar el servicio
https://marginalia-search.com/
https://www.marginalia.nu/log
Capaz ya lo sabés, pero para crawlear, si detectás que un blog está en Wordpress, el feed RSS tiene un parámetro paged para ir paginando y scrapeando posts en orden cronológico. -
los wordpress tienen sitemap (si el dueño actualizó el sitio en los últimos 10 años 😋) el problema se da con los de blogger y los que usan plataformas minimalistas. Como no voy a armarme un spider super complejo sólo indexo lo que el autor pone al servicio del público, si no le interesó tener un sitemap, es su responsabilidad 😁🤷
No quiero crear un buscador tan complejo como el del autor, simplemente algo más sencillo donde encontrar blogs interesantes, estoy dejando a la mayoría de los sitios grandes afuera y los foros también, no tengo capacidad de indexar tanto, pero posteos del RSS y del Sitemap, todo adentro (si me lo permite cada autor, claro)