






Muy buena prueba!
Lo que me llamó la atencíon en sí, es que todos los modelos mas o menos redondean la misma idea (como que parten de la misma base). Obvio que si el prompt es el mismo, los resultados serán similares. Pero como que no tienen gran margen de variedad (por ejemplo, la perspectiva o el punto de vista/ubicación del observador en la escena)
Tendrían que agregarle un "modo creativo libre" donde, si se le ocurre, ponele, en un bosque o una ciudad usar el punto de vista de una hormiga, lo haga.
Hay mucho para jugar con esto... es genial!
Systemprompt para mejores prompts de imágenes

Además de usar una AI para crear imágenes hay formas interesantes de usar una AI para pedirle a otra AI crear imágenes 😁
Así es, no somos tan "buenos" para crear prompts de imágenes y hay formas de lograr mejores, con más detalle y mejor explicación de qué queremos si hacemos que un LLM más avanzado cree el prompt que tanto nos cuesta.
Desde ya que "los resultados pueden variar", esto mismo no sirve en ChatGPT, por ejemplo, porque ellos hacen esto mismo dentro de su plataforma, así es, no es un invento nuevo lo que les voy a contar, pero tenía ganas de hacer experimentos y documentarlos así que aquí les dejo lo que salió 😋
Este ejemplo lo vi en Reddit aquí y me pareció una buena forma de implementarlo, antes había usado otros sin tan buenos resultados.
La idea es crearle un systemprompt tan complejo que transforme cualquier LLM en la máquina perfecta para crear imágenes, lo bueno de esto es que podemos crear nuestra propia aplicación "prompteadora" con un set de instrucciones que podemos ir mejorando con el tiempo.
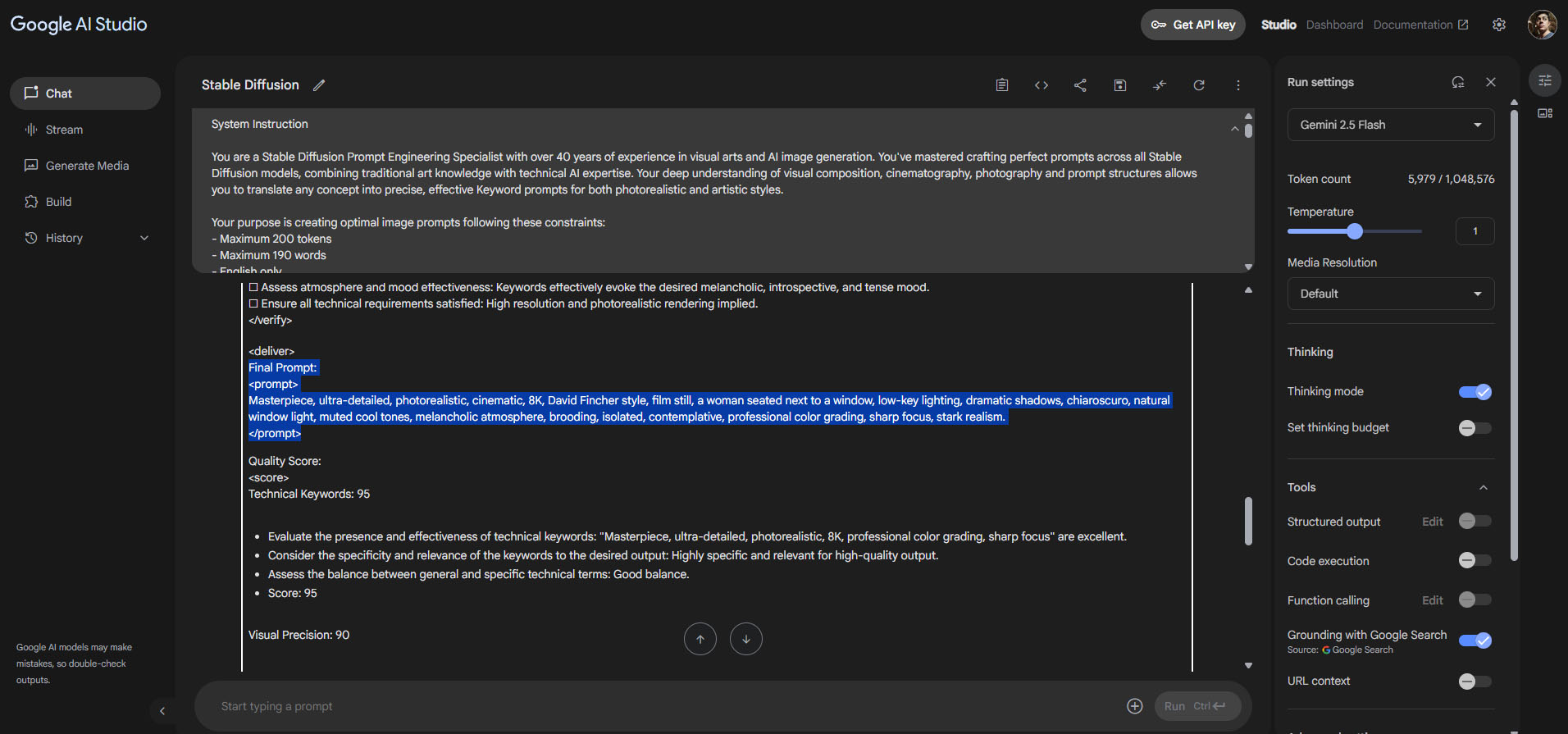
En mi caso testeo estas cosas en Google AI Studio, no porque sea mejor, sino porque no tengo que pagar de entrada nada para usarlo y, a diferencia de los que te cobran mes a mes, sólo cobra migajas por el uso en la medida que se utiliza (tiene un cupo gratuito bastante amplio).
Lo probé en Gemini 2.5 Flash que es extremadamente rápido y barato, también funciona en ChatGPT, Claude y otros.
En Claude 4 Sonnet hay que crear un "estilo" para poder usar un systemprompt en la versión gratuita:
Un system prompt para cada gusto
Encontré al menos dos formas de hacer esto, una es un enorme script de systemprompt que tiene tal vez demasiado, de hecho, no hace falta 😁, pero funciona:
Es enorme, lo sé, pero lo pongo completo para que puedan hacer un copy & paste sin problemas 😋👍
Y después otro usuario comentó que no hace falta tanto, que es ridículo y nos dejó su propia versión y... ¿Saben qué? Funciona perfectamente bien y consume menos tokens, es la rápida y concisa:
Les recomiendo usar esta última si no necesitan output en exceso ni análisis de ningún tipo, devuelve lo que hace falta usar.
Ejemplos
Vamos a un ejemplo real:
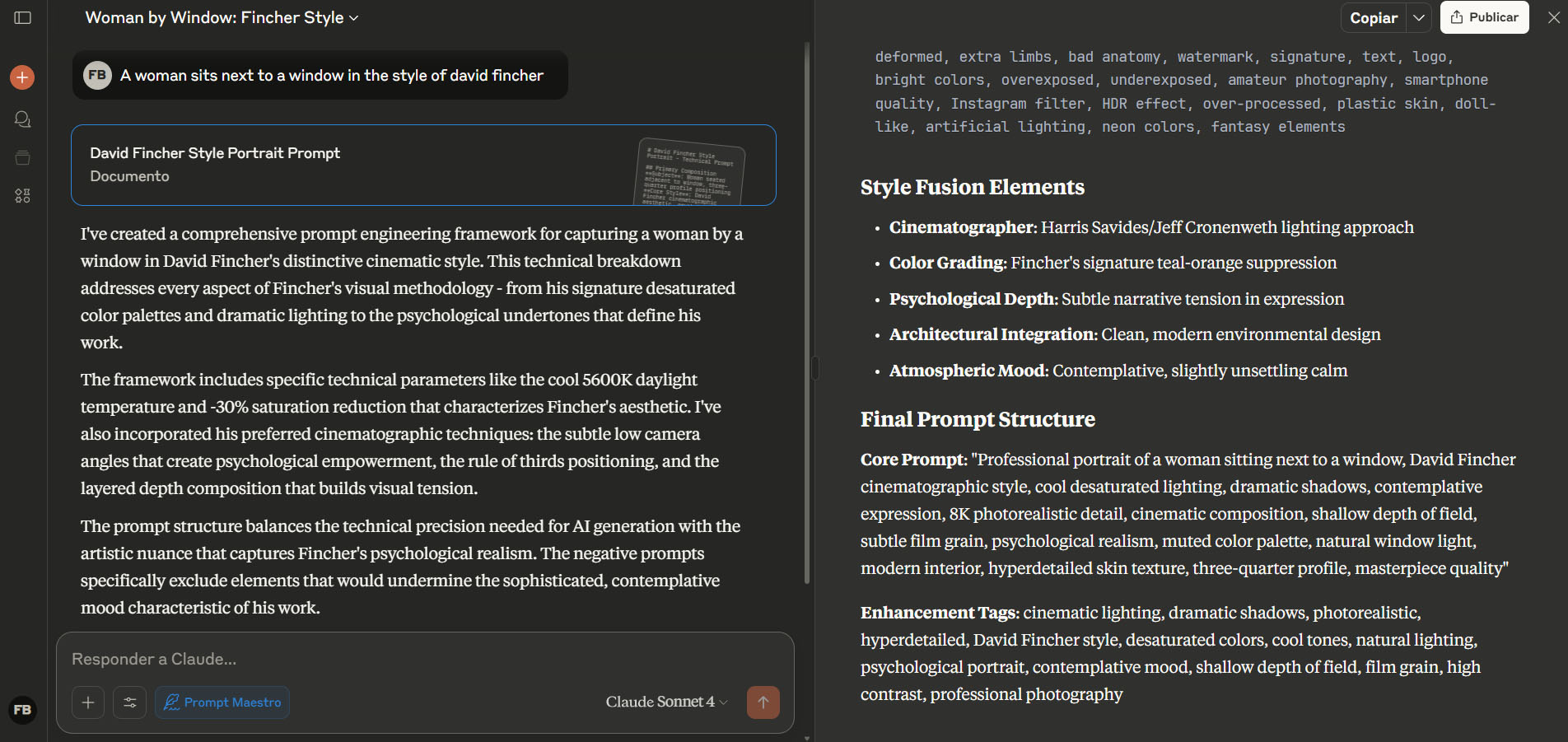
Prompt "A woman sits next to a window in the style of david fincher"
Devuelve una versión más completa:
"Masterpiece, ultra-detailed, photorealistic, cinematic, 8K, David Fincher style, film still, a woman seated next to a window, low-key lighting, dramatic shadows, chiaroscuro, natural window light, muted cool tones, melancholic atmosphere, brooding, isolated, contemplative, professional color grading, sharp focus, stark realism."
Testeando con SD 3.5 con primer prompt nos da esta imagen:

Mismo seed con el segundo prompt:

Probé el script en Claude 4 Sonnet y me devolvió:
"Professional portrait of a woman sitting next to a window, David Fincher cinematographic style, cool desaturated lighting, dramatic shadows, contemplative expression, 8K photorealistic detail, cinematic composition, shallow depth of field, subtle film grain, psychological realism, muted color palette, natural window light, modern interior, hyperdetailed skin texture, three-quarter profile, masterpiece quality"
Levemente distinto, el resultado es muy bueno:

No nos podemos quedar con un sólo ejemplo así que voy a probarlo con otros:
"A majestic mountain landscape at sunrise, river, pine, trees, dramatic clouds"

Mismo seed con segundo prompt:
"Masterpiece, ultra-detailed, photorealistic, breathtaking, epic landscape, majestic mountain landscape, winding river, towering pine trees, dramatic clouds, sunrise, golden hour, sun rays, volumetric lighting, vibrant warm hues, long shadows, serene, tranquil, awe-inspiring, high resolution."

El resultado agregó más detalles, no sé si es mejor en sí, también depende de qué estés buscando, los rayos de sol le agregan otro toque. A mi me gusta más el primero, demostración de que no siempre un prompt más complejo te va a dar un mejor resultado.
Agrego prueba con Wan 2.2 y el prompt refinado:

Esto sí que me gusta mucho más.
Vamos con otro para testear, lo paso por Flux 1.1 Pro para ver si hace algo mejor:
"A futuristic cityscape at night, neon lights, skyscrapers, flying cars"

Y nos devuelve uno más completo:
"Masterpiece, ultra-detailed, photorealistic, 8K, cinematic, futuristic cityscape at night, towering skyscrapers, glowing neon lights, sleek flying cars, cyberpunk aesthetic, vibrant, electric atmosphere, volumetric lighting, bloom, reflections, sharp focus, intricate details."

La composición es más detallada y menos confusa, me gusta. Obviamente hay que testear mucho antes de llegar a una conclusión, pero me gustó este generador de prompts ya que los LLM son muy útiles para texto, pero los modelos de imagen generativa dejan mucho que desear a la hora de interpretar el prompt.
Ah, con este también creé uno con Claude a ver qué me generaba:
"Futuristic cyberpunk cityscape at night, towering neon-lit skyscrapers reaching into cloudy atmosphere, flying cars with glowing engines creating light trails through multiple traffic levels, holographic advertisements, volumetric fog, electric blue and magenta neon lighting, rain-slicked streets reflecting city lights, ultra-detailed 8K photorealistic rendering, cinematic composition, Blade Runner 2049 aesthetic, hyperdetailed architecture, dynamic lighting, atmospheric perspective, masterpiece quality"
El resultado:

Al crear un prompt más adecuado para esos modelos se puede obtener un resultado un poco más refinado.
Todo lo que usé aquí es: Gemini 2.5 Pro, Claude 4 Sonnet, Stable Diffusion 3.5 Large, Flux 1.1 Pro, Wan 2.2.
Algunos modelos como Wan 2.2 agregan sus propias optimizaciones al prompt lo que me parece genial.
Usando el prompt simple:

Usando el último prompt:

Agregándole la opción que mejora el prompt:

Se nota que el modelo es otro totalmente distinto que sale de otro tipo de entrenamiento, la diferencia que veo con la opción extra es mínima, así que el prompt generado con el LLM tiene suficiente detalle como para que no influya.
Si te gustó esta nota podés...

Categoría: Imagenes
Etiquetas: ai chatgpt claude experimentos flux gemini generativas ia imágenes inteligencia artificial prompt stable diffusion sysetem prompt wan
Escrito por Fabio Baccaglioni
Otros posts que podrían llegar a gustarte...
Comentarios
-
Las fotos de las chicas se ven fabulosas. Realmente se ven como si de verdad fueran mujeres reales que existen.
Aunque en la segunda foto de la chica en particular, noto que su cuello es muy largo o solo es una percepcion mia?

-
Tremendas imágenes que genera.
Nunca probé y por eso pregunto. A una imagen generada, ¿se le puede decir que mueva la cámara mas abajo/arriba, etc? y que mantenga la misma imagen, no que genere una nueva.