Quien le roba a un ladrón, destila el control

Esta es una de esas paradojas modernas que me encantan, los chinos se pusieron a "destilar" modelos de AI como Claude y los de Anthropic lloran que les "roban".
Hasta aquí no nos sorpendería nada, empresas chinas fraguando cuentas para clonar algo hecho en occidente es básicamente el modus operandi del país oriental en toda industria, pero he aquí el dilema ¿Están robando?
Todos los modelos de Inteligencia Artificial están basados en robo sistemático de toda obra cultural generada por la humanidad, condensada en un modelo y luego nos la revenden como si fuese un trabajo original... que no lo es. Entonces ¿Ladrón le roba a ladrón? ¿Qué significa "destilar"?
Qué es la "destilación" de un modelo
Primero, para los que quieran entender un poco más el contexto técnico, expliquemos de qué hablamos cuando nos referimos a "destilación" que nada tiene que ver con pasar por una barrica de bronce una bebida espirituosa 🤪
La "knowledge distillation" es una metodología para poder sacar de un mega-modelo uno más pequeño, que conserve gran parte del conocimiento y use menos memoria, es muy usada por todos los que venden AI en este momento, OpenAI, Anthropic, Meta, etc.
El modelo "maestro" se usa para entrenar un modelo "alumno" reduciendo su peso, dándole, en el proceso, una versión acotada de todo el proceso que necesitó para predecir una respuesta y la palabra siguiente.
Por ejemplo, si durante su procesamiento el modelo maestro te da como respuesta "perro" durante ese proceso decidió entre tres o cuatro palabras hasta llegar a esa, cada una con una probabilidad, al final sólo te muestra "perro".
Si esta palabra tenía un 70% de probabilidad y "lobo" un 25%, eso no te lo muestra. Ahora bien, en la destilación se busca instruir al modelo "alumno" con esos otros porcentajes, dejando afuera los menos útiles como 5% por "gato", así que reducimos notablemente el peso dejando lo "mejor" de lo que predice el modelo mayor.
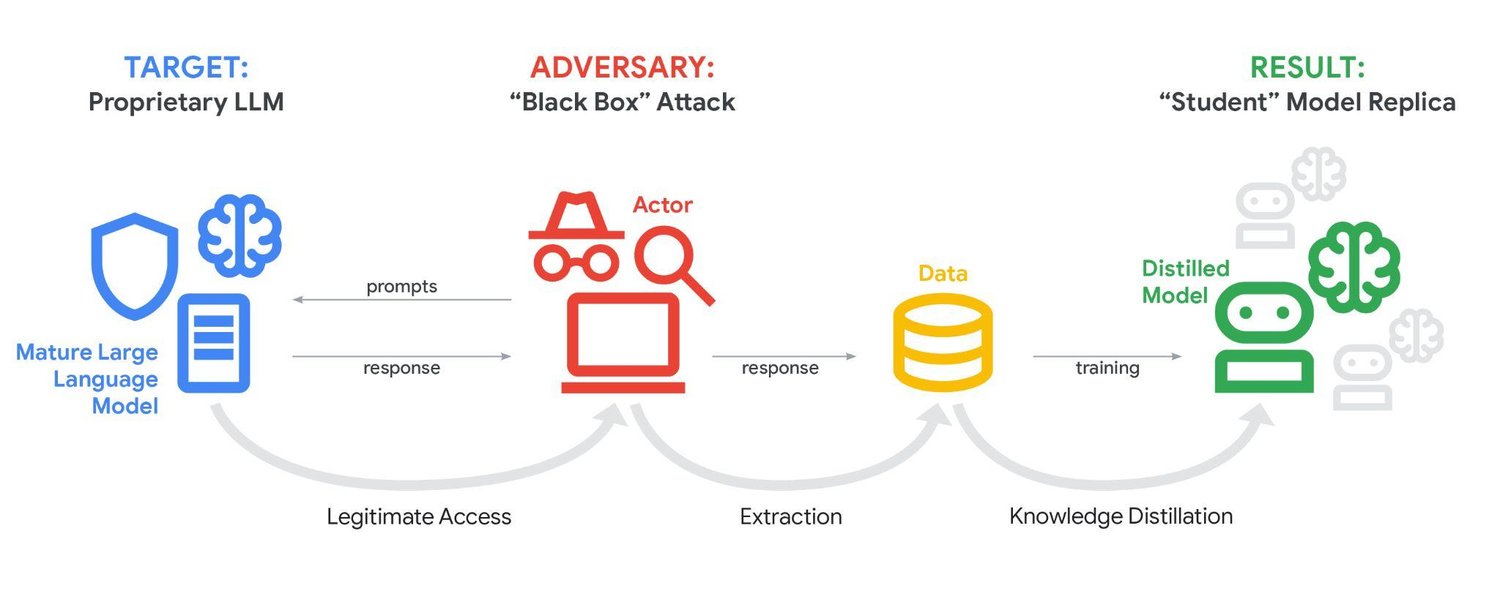
¿Qué tiene que ver esto con lo que hacen los chinos? Pues bien, sin acceso al modelo mayor igualmente se puede "destilar" en una versión mucho más tosca (si quieren detalles más técnicos lean el paper de Geoffrey Hinton, Distilling the Knowledge in a Neural Network).
Aquí ya no se tiene acceso al "maestro", sería una versión black-box donde el truco está en generar pares sintéticos de pregunta-respuesta, cambiar la temperatura (el parámetro que te da respuestas más variadas o más determinísticas) y ver qué resultado te da y cómo varió.
Se le suele llamar "imitation learning" porque es bastante más limitado y menos costoso, es lo que usualmente se usa en modelos abiertos como Alpaca, Vicuña, etc.
El truco chino
La empresa Alibaba es acusada por Anthropic de crear más de 25.000 cuentas falsas y unas 28.8 millones de interacciones contra el modelo Claude para "destilar" sus propios modelos a partir del trabajo de entrenamiento que hacen ellos.
Usando proxies de máquinas personales, que posiblemente ni saben que están siendo utilizadas para esto, logran evadir las protecciones de la plataforma y acceder sin que nadie lo note, miles y miles de requests.
Aclaremos que todo el trabajo de entranamiento nace de tomar el conocimiento escrito por la humanidad y procesarlo sin pedir permiso a nadie.
Aquí es donde entra el "ladrón roba a ladrón" que es el quid de la cuestión, desde Anthropic se creen víctimas, pero su "trabajo" nunca fue el de creación de toda esa información, es como que tomes un archivo, lo comprimas en .zip y te enojes cuando alguien copia el archivo zipeado.
Desde ya que es mucho más que eso, Anthropic es quien pagó las cuentas de la electricidad, coleccionó toda la data e inclusive tiene a otras empresas comprando saldos de libros abandonados, escaneándolos y pasándolos por OCR, todo un trabajo que los chinos ni se molestan en hacer, pero que no deja de ser... bueno, lo que toda la industria del copyright se la pasó llorando durante años.
¿Es ese conocimiento público? En muchos casos ya está probado que no, pero la "causa mayor" impulsa a las empresas norteamericanas con la filosofía de "arreglaremos luego", y ahí hay una gran diferencia con los chinos: los norteamericanos asumen que tendrán que arreglar con quien reclame y eso costará dinero, los chinos no.
Qwen?
Si quieren utilizar un modelo supuestamente chino, Qwen es el destinatario de todos estos esfuerzos de Alibaba para clonar Claude (o el que sea), y es muy bueno como modelo, es libre y gratuito, si quieren pueden descargar una versión cuantizada para usar en su propia PC.
El "Model Extraction", también llamado "model stealing", tiene sus limitaciones, el primero es crear todos los pares prompt → respuesta suficientes para que realmente sirva de algo, eso implica una inversión muy fuerte en proxies y cuentas apócrifas que siempre será más barato que crear el modelo "maestro" inicial (si no ni lo harían, está claro).
El límite real no es el acceso, es la capacidad del alumno
Acá está la trampa de "destilar un modelo más grande". La destilación no transfiere capacidad mágicamente a un base más chico. Si tu alumno es de 7B, no vas a meter dentro un frontier de cientos de miles de millones de parámetros por más datos que le tires. El maestro grande te da mejores datos de entrenamiento, pero el techo lo pone tu alumno y su escala.
Esta escala está en los datacenters de Alibaba donde la inversión del gobierno chino es gigante, por eso la preocupación de Anthropic por un lado y del gobierno de los EEUU al bloquear el acceso al modelo Mythos y Fable.
El paper de Berkeley "The False Promise of Imitating Proprietary LLMs" (Gudibande et al., 2023) mostró algo importante: los modelos imitadores copian muy bien el estilo y el formato del maestro, tanto que los evaluadores humanos los califican alto, pero no cierran la brecha en razonamiento ni en factualidad.
Aprenden a sonar como el modelo grande sin heredar su núcleo de capacidad. Y está el problema de cobertura: el conocimiento del maestro es enorme, tus queries muestrean una porción ínfima, así que rendís bien en lo que consultaste y mal en el resto.
¿Es ilegal? Pues bien, según las leyes de EEUU "ponele", pero para las leyes Chinas no, entonces ¿Puede cambiar algo? No lo creo, si la herramienta está abierta a todo el mundo es inevitable que intenten destilar.
Existe la posibilidad de cierto "watermarking" en las respuestas, Google lo hace, pero ¿por qué habría de molestarle a Alibaba? No sólo se puede quitar, al usuario no le va a importar que Qwen tenga el estilo de ChatGPT o Claude, le da igual.
Ya en 2025 se había confirmado que DeepSeek había destilado salidas de ChatGPT, así que es una guerra que no creo que puedan controlar. Otros modelos que han hecho esto son Minimax y Moonshot AI.
Si quieren probar Qwen y tienen un GPU de los grandes con más de 16GB de VRAM, pueden probar en LM Studio con el modelo Qwen 3.6 27B que pesa unos 18GB 😁, en mi caso, con apenas 6GB de VRAM es sencillamente imposible. (también está el 35B de 22GB)
Idea final: DeepSeek destila de Qwen y así se van mezclando entre todos los modelos libres, por ahí el verdadero camino está por ese lado, que todos los modelos converjan en uno solo, libre y abierto, así el conocimiento de la humanidad no es "robado" sino compartido, como debe ser. Adiós al copyright, adiós al robo.
Si te gustó esta nota podés...

Escrito por Fabio Baccaglioni
Otros posts que podrían llegar a gustarte...





